
Blog
Blog-posts are sorted by the tags you see below. You can filter the listing by checking/unchecking individual tags. Doubleclick or Shift-click a tag to see only its entries. For more informations see: About the Blog.

Hello everyone!
We are pleased to announce that from now on VL language design ideas will be specified in public.
This allows you to see
- which areas we identified to work on (quests)
- what ideas we came up with to fix those issues (proposals)
- which proposals got favored over other proposals (decisions)
- which proposals got moved onto which milestone
But it also allows you to join forces with us. Since in the end, it's all about your patches, we appreciate your feedback.
We decided to start clean: For now, we didn't throw all our language ideas into this repository. In its current state, we only see issues that came up in the last days, so the selection of issues is quite incomplete. Other ideas that might be more important and didn't come up in these days will eventually make it there as soon as they come up again.
We'll address quests by you or us with proposals that might be fresh or have been around for some time. We'll try to communicate different approaches and the pros and cons. And we'll try to single out very few issues that are just too promising to not having a shot at. Changing the language is quite hard, so expect an insane ratio of proposalsThatSoundNice / featuresComingSoon.
We were quite impressed by how this was handled by the C# Language Design Team. So we copied the approach.
Sometimes it's hard to distinguish between the language and ways of expression within the language. You just search for a way to address a certain problem. How would I structure my patches? We'll allow these so-called design patterns to be discussed in this repository as we want the language to be able to follow well-established ideas on how to solve certain types of problems. Here is an example.
But for now: Welcome to the club! \o/
helo evvvveryone,
we're preparing for a vvvv beta39.1 release and here is a first release candidate. As you'll see in the change-log it is a rather minor update with only fixes. It does not yet include the anticipated update to latest VL, which we save for upcoming beta40. We just want to get another stable version out before such a bigger update that including latest VL will mean.
Remember that via VL you have access to many more goodies. Here is a convenient list of VL nugets that work with this release. To learn how to install nugets please consult this documentation and then use these commands to install them:
(To use the latest version of these nugets you'll have to wait for upcoming beta40 or use gamma2020.1)
nuget install VL.OpenCV -Version 0.2.141-alpha nuget install VL.Devices.Kinect2 -Version 0.1.45-alpha nuget install VL.Devices.Realsense -Version 0.1.7-alpha nuget install VL.GStreamer -Version 1.0.18-gadcd7f95e5
nuget install VL.Audio -pre nuget install VL.IO.M2MQTT -pre nuget install VL.IO.NetMQ -pre nuget install VL.2D.DollarQ -pre nuget install VL.2D.Voronoi -pre
If you have other public nugets that you tested to work with this release, please post them in the comments so we can all mention them in the upcoming release notes!
Download
vvvv beta39.1 x64 RC1
vvvv beta39.1 x86 RC1
And as always, please test and report your findings!
This is my talk at Ircam earlier this year, where I tried to introduce vvvv gamma to an audience not necessarily familiar with vvvv but most likely already with the idea of visual programming. Given the fact that Ircam was the birthplace of Max and PD which are still both in heavy use there.
In 25 minutes I tried to give a glimpse at vvvv by focusing on four things that I believe make it shine:
- Loops
- Multithreading
- Object Oriented Patching
- Extensibility
Also I pretended that it is completely normal to already have a 3d engine with it...
For talk description and recording of other talks see: https://medias.ircam.fr/xcc0abe
And here we go!
Only about a year after the first public preview of vvvv gamma we hereby announce what will be the final round of previews:
The vvvv gamma 2020.1 series.
We have a code-freeze. This is essentially what will be in the final release. We'll only be adding to documentation and fix showstopper bugs, should they come up. Of course we're aware of many more issues but we hope at this point to have squashed all the biggest buggers and are confident to release a first stable version within the next weeks.

What's new compared to the vvvv beta series
LanguageBesides staying true to its nature of being a an easy to use and quick prototyping environment, vvvv is also a proper programming language with modern features, combining concepts of dataflow and object oriented programming:
|
Node LibraryWhile for now the number of libraries we ship is limited, the fact that you can essentially use any .NET libary directly mitigates this problem at least a bit. Besides there is already quite some user contributions available in the wip forum and here is what we ship:
|
Learning
The integrated help-browser comes with a lot of examples and howto-patches and a growing number of video tutorials is available on youtube.
Pricing
We've announced the pricing model of vvvv gamma in a separate post. Until further notice, the previews of vvvv gamma are free of charge but due to its preview-nature we don't recommend using it in commercial scenarios yet.
Download
Here you go: vvvv gamma 2020.1 preview 0040
Changelog:
Upcoming
0040 27 03 20
- Re-enabled very rough and highly experimental support for attributes in roslyn backend - Elementa inspector patch working again
- Fixed a crash related to recursive type rendering
0032 24 03 20
- Fixed null pointer when opening patches making use of pin exposure
- Fixed a few regressions introduced with one commit in previous version which caused issues like https://discourse.vvvv.org/t/2020-1-elementa-bang-broken/18354/3
- Fixed Args node outputs
- Added base64, url and html encoding nodes
- Added more HowTos
Compared to the 2019.2 series
- Args node now handles options without parameters
- Added a bunch of new simple howto patches
- Added clock to display call frequency of runtime value in tooltip
- Added ToImage [IReadOnlyList]
- Removed culture specific resource assemblies and disabled pdb files in release build
- Fixed a sync issue in UI when disabling manual signature and fixed pin synchronization when using "Connect to signature"
- Visualize model synchronization step in progress bar
- Using Memory<byte> instead of unsafe IntPtr in IImageData
- Fixed deserialization of collection of characters
- Fixed assignments to pads sometimes having a side-effect on other pads with that same name
Ideally this will be the last preview, realistically we'll have to release some more. So please check back often and report your findings in the chat, forum or a comment below!
Yours truely,
devvvvs.

As we near the official release of vvvv gamma, let's take a minute and look back on what happened so far.
Here's a compilation of every vvvv gamma and VL related blog post.
We hope it serves as both, an overview of historic developments and a helpful learning source for VL users that might have forgotten some along the way:
2020
Announcement for stable release of vvvv gamma 2020.1: vvvv-gamma-2020.1-release
Download and changelog of vvvv gamma 2020.1 preview: vvvv-gamma-2020.1-preview
Download and changelog of vvvv gamma 2019.2 preview: vvvv-gamma-2019.2-preview
Introducing help patches per node: vl-help-patches
A roundup of the latest features of the VL.Xenko 3d rendering engine: vl-xenko-3d-engine-update-3
2019
Reworked licensing model: vvvv-gamma-licensing-2
New web presence for vvvv gamma: visualprogramming.net
Introducing the HelpBrowser for easy in-app learning: vl-getting-you-started
Big feature, export executables: vl-exporting-an-application
Announcing our cooperation between Xenko and vvvv: vvvv-meets-xenko
Background information on the VL compiler overhaul: vl-new-roslyn-based-backend
Public VL presentation on a .NET developer conference: vvvv-at-dotnextconf-moscow-video
Download and changelog of vvvv gamma 2019.1 preview: vvvv-gamma-2019.1-preview
First draft of the new licensing model: vvvv-gamma-licensing
Switching all VL libraries to Xenko vector types: vl-switch-to-xenko-math
Tooltips and runtime value inspection are pretty and can be patched: vl-tooltips
IOBoxes are now feature rich and can handle collections: vl-the-big-iobox-update
Big progress on computer vision: vl.opencv-release-candidate
Dynamic input/output pins are here: vl-input-and-output-pin-groups
Understanding the difference between definition and application: vl-the-application-side-of-things
Added regular expression nodes: vl-regular-expressions
2018
Public vvvv gamma and roadmap announcement: the-road-to-gamma
Progress report on the VL.Xenko 3d rendering engine: vl-xenko-3d-engine-update-2
Improvements on the VL.Skia 2d rendering engine: vl-skia-update
Initial progress report on the VL.Xenko 3d rendering engine: vl-xenko-3d-engine-update-1
Announcing the VL.Xenko 3d rendering engine: vl-threedee
Announcement and insight into the VL.Skia 2d rendering engine: vl.skia
Reading and writing VL data types to disk: vl-serialization
Explaining the structural elements of VL documents: vl-groups-and-categories
Beatify and organize your patches with frames: vl-frame-your-patches
Update on file read/write: vl-improved-file-io
Big cleanup of the VL.CoreLib: vl-corelib-cleanup
Working with different threads and main loops: vl-patch-your-own-mainloops
Announcement of computer vision for VL: vl-opencv-is-in-da-house
The fundamental building block for timelines and searches in sorted collections: binary-search-for-your-keyframes
How to connect image data types of different libraries with each other: vl-image-exchange-interface
Prepare GPU data directly on VL to use it with dx11 rendering: dynamic-dx11-buffers-in-vl
2017
Better debug features: vl-one-frame-at-a-time
Maintenence release for Arduino/Firmata: firmata-updates-and-fixes
Import any .NET library (!) into VL: vl-using-.net-libraries-and-writing-custom-nodes
Parser for serial data and other byte streams: new-tokenizer-nodes
Announcing reactive/async programming with observables: vl-reactive-programming
Nodes for working properly with MIDI: vl-event-based-midi
Parse, modify and write XML and JSON: vl-xml-and-json-nodes
Update on 2D and 3D editing: editing-framework-update
Nodes to work with network sockets: vl-networking-and-async
2016
Nodes for Arduino/Firmata: firmata-second-service
Nodes to work with input gestures: zoom-pan-rotate-touchgestures
Cummulative VL update (performance, clock and time, high DPI): vl-progress-report-4
Nodes for working with the file system: vl-many-paths-lead-to-rome
Initial file handling nodes: let-me-present-to-you-file-io
Cummulative VL update (UI improvements): vl-progress-report-3
Cummulative VL update (UX improvements): vl-progress-report-2
Cummulative VL update (new UI elements): vl-progress-report-1
Huge update overall and new downloads: vl-midsummer-nights-dream
VL progress report (pads, fields, properties, operation signature): vl-spring-update
VL progress report (patch structure, categories, library): vl-winter-update
Learn about the fundamental data types of VL: integer-and-primitive-types-in-vl
Nodes for 2D and 3D editing: introducing-the-editing-framework
2015
VL progress report (new devices, library, nuget, UI): vl-autumn-update
Working with value ranges: mapping-and-ranges-in-vl
Understanding spherical and cartesian space: polar-spherical-and-geographic-coordinates
VL progress report (library, eye tracker, UI, loops): vl-summer-update
Add type annotations to properties: vl-type-browser-now-in-alpha-builds
Community feature voting: vl-feature-voting
First official download of VL: vvvv50-vl-pack-alpha
Preparing for the first launch: 50-pre-release-roundup
Understanding data type patches: 50-custom-datatypes
Understanding generics: 50-generics
2014
Understanding properties aka. fields: 50-properties
Understanding operations aka. methods: 50-colors
Initial thoughs: 50-that-next-big-thing.-an-overview.
Object oriented patching for the masses: 50-vl-features-i-a-patch-is-now-a-class
The very first applications built with VL: 50-the-humble-quad-bundle
Anything to add? Let us know in the comments.
yours,
devvvvs
Moments later,...
...we're announcing the immediate availability of the vvvv gamma 2019.2 series of previews, finally including one of the more anticipated features in vvvv history: Executable Export.
This means we are now in the final stage of the preview leading up to a proper initial release after the waves introduced by the new features in this series have been smoothed out.

What's new compared to the vvvv beta series
LanguageBesides staying true to its nature of being a an easy to use and quick prototyping environment, vvvv is also a proper programming language with modern features, combining concepts of dataflow and object oriented programming:
|
Node LibraryWhile for now the number of libraries we ship is limited, the fact that you can essentially use any .NET libary directly mitigates this problem at least a bit. Besides there is already quite some user contributions available in the wip forum and here is what we ship:
|
Tutorials and HowTos
A growing number of video tutorials is available on youtube.
Pricing
We've announced the pricing model of vvvv gamma in a separate post. Until further notice, the previews of vvvv gamma are free of charge but due to its preview-nature we don't recommend using it in commercial scenarios yet.
Download
Here you go: vvvv gamma 2019.2 preview 321
Changelog:
Upcoming
321 04 03 20
- Fixed copy-paste of output pins not merging correctly into target patch
- Fixed patch pins not always being synced to nodes with the "Connect to Signature" flag
- Do not create empty regions (nodes without a patch) when syncing to a node definition which lost its delegate input
- Should an incremental compilation of a project fail, try from scratch before giving up.
- Fixed implicitly inserted CreateDefault node not being tracked in dependency graph - fixes backend crash when modifying it
- Fixed assembly initializers being called far too often leading to long hotswap times in bigger projects
- Fixed regression that enums don't have System.Enum as super type anymore (was for example breaking VL.Devices.Kinect2)
- Fixed vvvv.exe becoming a ghost process when crashing on startup
- Fixed disposable interface being added twice when VL.CoreLib was missing - caused subsequent emit crash
- Only load project assembly from cache if all its dependencies have also been loaded from cache - fixes emit error when dependent project was modified
- Backend will now unload not needed project states
- Faster RGBA to RGB conversion (IImage to SKImage)
- Fixed cast exception triggered by node browser when browsing through nodes from assemblies
- Fixed various crashes when opening a completely broken document structure (missing assemblies, missing documents etc.)
- Fixed file/string readers not eliminating BOM
- New nodes Loop [Observable], Subscribe (Provider) [Observable], Using (Provider) [Observable] and moved PollData, PollResource from Resources to Observable category
- New region Loop [Observable] managing internal state as well as giving access to cancellation and observer to optionally push data
- Subscribe [Observable] returning a provider which manages the lifetime of the upstream observable sequence
- PollData and PollResource now stateful internally thanks to making use of new Loop
- Removed recently introduced TryOpen/Retry/RunOn [Resources] nodes as they turned out as hard to use (deadlock) and not necessary
- Added new struct ArrayBuilder used by two new nodes:
- StoreSequence [Collections.MutableArray] to efficiently either grab an upstream array from a sequence or copy its content into an internal array which will then get exposed.
- HoldLatestCopy [Collections] to efficiently copy data pushed from a background thread into the main thread
- Bunch of minor performance improvements to VL.Skia by making use of methods provided by the System.Runtime.CompilerServices.Unsafe class and calling SKCanvas.SetMatrix in Transform nodes, not rendering nodes
- Fixed allocation issues of Points [Skia.Layers] by exposing internally used DrawPoints via ReadOnlySpan
- Fixed assignment of higher order regions not being carried over to expanded patch
- Ensure names of emitted assemblies are unique even after reloading a document
- Type Unification got even more robust and versatile. Better type renderings and type error messages.
- generic node applications with generic pins (like "a Asset") previously just lead to type "Asset" for the generic pin for as long as the pin was still unconnected. This way you often had to force connections. Now these type parameters stick around leading to not calling the node until to the point where you actually connect to something.
- types can look like this: "a Asset". This is a short rendering for a constrained type parameter "T1 where T1: Asset". F# also has an abbreviation for types like this. They call it flexible types.
- types can look like this: "Sequence (Ungeneric) & IReadOnlyList<T>" which is a beautified rendering for "T1 where T1: IEnumerable, IReadOnlyList<T>"
- if necessary (like on recursive types) the type parameter will not get hidden. "T1: IReadOnlyTree<T1>" is not hiding the T1 behind an "a IReadOnlyTree<T1>" in order to make clear that it references itself.
- invalid type annotations (those where the type arguments of the user break the constraints of the type parameters) lead to proper error messages.
- quite less emit problems due to more robust type unification
- Added RemoveAll for Spread and SpreadBuilder
- Fixed Random node not being thread safe
- Fixed ForEachParallel crashing with input count of zero and modified it so it returns a spread builder instead of a spread to avoid allocations
236 18 02 20
- added ShowOrigin setting
- More type inference fixes
- Fixed primitive types not having any super types like IComparable (was reported in chat by sebl)
- Fixed type constraints on higher order region with one single patch not properly generated should the name of the inner patch have changed
- Fixed "auto connect to signature" of patches like CreateDefault which have a fixed set of pins
- Fixed output pin groups of type Dictionary<string, obj> not working anymore when pin on application side was annotated
- Fixed compiler crash when having a generic type annotation in a patch
- Fixed CLR array types not being mapped to type symbols
- Removed Spread.Pin/Unpin - same functionality is available through much safer TryGetMemory/Pin -> MemoryHandle.Dispose path
- Fixed pixel format being swapped from R8G8B8 to B8G8R8A by SKImage.FromImage node
- Fixed null pointer when trying to navigate into patches of completely broken documents
- Fixed higher order regions not working when definition added an inner pin
- Added a few convenience nodes for resource providers useful when opening and polling devices. Even though not yet released they already look promising for devices like Kinect or Astra.
- Fixed minimal changes on solution made by compiler getting discarded (pin order somtimes not updating on application side)
- Fixed pin group builder (ModifyPinGroup) changing the model when it shouldn't
- Fixed repeat loop not working on inputs of type T where T : IReadOnlyList
211 07 02 20
- Don't use BOM in UTF8Encoding
- Backend generates new lines on its own without having to rely on super heavy NormalizeWhitespace function. This should get rid of very long compile times when traversing deeper into a library. Debugging the generated C# code with Visual Studio will only work properly when running with -debug and -nocache flags
- improved type unification cleverness and stability
- Helpbrowser: chat language buttons added
- AppExporter "Export" button gives immediate feeedback
0193 31 01 20
- fixed pin-reordering in signatures as reported here: https://discourse.vvvv.org/t/2019-2-0081-pin-reordering-buggy-behavior/18132
- Removed private flags between our package dependencies as it caused msbuild to skip copying certain assemblies coming from VL.CoreLib as well as making our packages smaller.
- Fixed parts of patches being grayed out and when traversing inside becoming all good - compiler was missing one iteration in recursive blobs -https://discourse.vvvv.org/t/lazy-type-inference/18066
- improved support for helppatches
- Reworked error handling of CreateDefault and RegisterServices operations
- Extended the general renaming code path to handle all cases and removed obsolete rename commands
- The Micorsoft Build Tools 2019 are now optional. If not installed the Export menu entry will be disabled
- Removed the .vl suffix on generated executable and fixed Run button
0169 22 01 20
- Couple of fixes in type unification algorithm - fixes for example VL.Devices.RealSense
- Exporter uses nuget restore to figure out what assemblies are already referenced by packages. Fixes export of VL.OpenCV as well as reported issues like https://discourse.vvvv.org/t/export-application-problem-superfluous-system-reactive-reference-2019-2-0125/18145 https://discourse.vvvv.org/t/app-export-failure/18107
- Fixed pins not highlighting in valid cyclic connection attempts like FrameDelay
- Fixed wrong VL factory being used in exported apps - type names used by serializer were different
- Fixed target code when not implementing an interface yet - https://discourse.vvvv.org/t/exception-when-implementing-an-interface-2019-2/18122
- Do not try to restore packages without a version on export - fixes export of VL.DBSCAN which has buggy reference to non-existing VL.CoreLib.VVVV
- Fixed missing or wrong assembly references in exported projects.
- Fixed default value of delegates in generic patches. CreateDefault operations will be auto-generated for all delegate types.
0140 09 01 20
- Fixed ToObservable (Switch Factory) - used by many reactive nodes - not calling the factory after the element type changed due to a hotswap
- Added HighDPI awareness to App.config for exported apps
- Fixed stack overflow when patching a CreateDefault - system will now generate an error as long as the output is not connected
- The default value of a record will again be cached in a static field
- Fixed serializer serializing auto-generated fields
- OSCMessage (Split) now returns timetag
- CTRL+Shift+F now also finds interfaces
- updated VL.OpenCV to 0.2.133
- fixed problem with pin-editor for serializable types like Rectangle
- Splash screen shows up in taskbar and has proper icon
- Counter Clamp/Wrap/Mirror reset under/overflow correctly
- NodeBrowser now has a TextBox that can select/copy/paste
- Fixed regression that bang and press IO boxes would sometimes stick to true
0081 16 12 19
- Fancied up the helpbrowser
- Fixed problem scrolling in menu dropdowns: https://discourse.vvvv.org/t/main-menu-ui-scroll-with-mousewheel-within-dropdownmenu-lists/18083
- Fixed a crash in UI when creating a frame https://discourse.vvvv.org/t/creating-frames-throws-exception/18067
- Fixed crash in UI when trying to retrieve the default value of an imported generic typehttps://discourse.vvvv.org/t/2019-2-0026-cannot-create-iobox-tuple-t-t/18061
- Fixed apply node lifting being applied to nodes which already had an apply pin (like Console.WriteLine)
- Fixed crash when referencing an assembly like Bridge which tries to replace the whole mscorlibhttps://discourse.vvvv.org/t/gamma-x-2-nuget-import-error/18038
- Fixed regression that the "valid pins are ..." warning wouldn't show up when implementing an interface
- Type annotations on pads which point to a field will now truly be ignored and also cleared - was reported in chat by björn
- The version of the currently used package will now be written to disk. Allows to introduce converters for libraries at a later stage.
- Fixed regression that the Serializable attribute wasn't set on emitted classeshttps://discourse.vvvv.org/t/issue-with-serialization/18064
- Fixed regression that source packages (provided through command line arg --package-repositories) wouldn't get higher priority than installed oneshttps://discourse.vvvv.org/t/2019-2-0026-weird-behavior-of-package-repositories-arg/18077
0026 10 12 19
- Fixed loading of VL.Devices.RealSense
- Fixed empty error message on faulty type annotations
- When generating a C# project, local source packages without a nuspec will not get includedhttps://discourse.vvvv.org/t/exporting-fails-to-build-due-to-dependency-it-isnt-using/18043
- Fixed regression that nodes on auto-connect would show warning as well as their pins of unused fragments wouldn't connect to the default patch anymorehttps://discourse.vvvv.org/t/gamma-2019-2-connect-to-signature-does-not-work-in-this-region-even-outside-a-region/18048
0015 06 12 19
- Patch drawing is antialiased and icons are showing again
- Fix for drawing transparent PNGs
- Fixed regression that delegate regions wouldn't create their pins anymore
- Emit exception will show first error now as it's message
- Fixed specialized operations not being marked as unused if there containing type was - seehttps://discourse.vvvv.org/t/gamma-x-2-breaking-not-opening-old-patches/18036
Compared to the 2019.1 series
Features
- Export to executable
- Faster startup and less memory consumption due to precompiled libs
- Recursive operations and datatypes
- Runtime errors: marked node is now always correct
- Generated C# code can be debugged using Visual Studio
- Help patches (where available) open when pressing F1 on a selected node
Breaking Changes
Unfortunately this preview introduces some breaking changes. This means that projects that were working fine with 2019.1 previews may no longer work correctly with 2019.2 previews! If you encounter such a situation and cannot resolve it on your own, please get in touch via forum or chat! Here is a list of possible problems you may encounter:
- Existing patches may need additional type annotations due to changes in the type unification
- Execution order of nodes may be different if it wasn't explicitly expressed before
- Generic type parameters in an interface patch will now always belong to that defined interface (and not any of its operations)
- Not really breaking, still a change: Runtime errors: no values in tooltips when in pause state
For technical details please see the blog post about the New Roslyn based backend.
We'll update this blogpost with new preview-releases regularly. Please check back often and report your findings in the chat, forum or a comment below!
Yours truely,
devvvvs.
Help!
One of the most requested features for VL ever since was the support for help-patches. Obviously they had to come back, but it took us a while to figure out how exactly. One of the brainstorming sessions at LINK was especially helpful to sort out the details. Thanks everyone for your input...
Help Patches
So for the user it is just as before: Press F1 on a node that you need help for. Now what happens is:
- If a help-patch is found, it is opened and a bubble indicates the node you were looking for
- If no help-patch was found, a bubble indicates that no help-patch was found
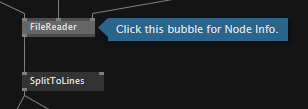 Help patch was found...
|
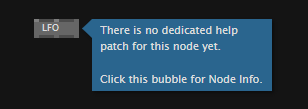 No help patch available...
|
In both cases, you can now optionally opt-in for more help: Click the bubble to open the help browser showing the nodes Node Info.
Node Info
Shows some info about the node plus 3 lists of how-to patches this node is used in:
- most relevant (the dedicated help-patch)
- still relevant
- list of other patches using this node (automatically generated)
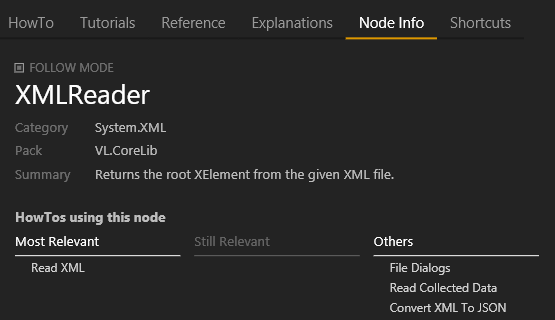
This should increase the chance of finding good info about how a node can be used in different scenarios.
When "follow mode" is active, you can click around in the patch and always get the node info to the last selected node.
Help Flags
Creators of libraries who want to provide help patches now use help flags to indicate relevance for a node. Read all about using help flags in the graybook.
Available for testing in latest previews!

Happy new year, evvvveryone! Welcome back and we hope you had some fine holidays. More than one year has passed since the last report. An update is well overdue. This post sums up last year’s (2019) progress on our upcoming 3d engine for vvvv gamma.
Xenko’s codebase is huge and even after one year, we are still in explorer mode. But help is near! As you might have read, Xenko’s lead developer Virgile Bello aka xen2 is now with us in Berlin. While his main focus is maintaining Xenko and building a community around it, he also helps us to achieve our goals faster by answering questions and fixing bugs that we encounter.
As it is still early, for each technology we work on, we try to focus on creating only the basic nodes required to get a working prototype. Because if we have to change something fundamentally, every node has to be adapted. Nevertheless, there are tons of nodes already.
Besides many little things, here are the main topics we worked on:
Scene Graph
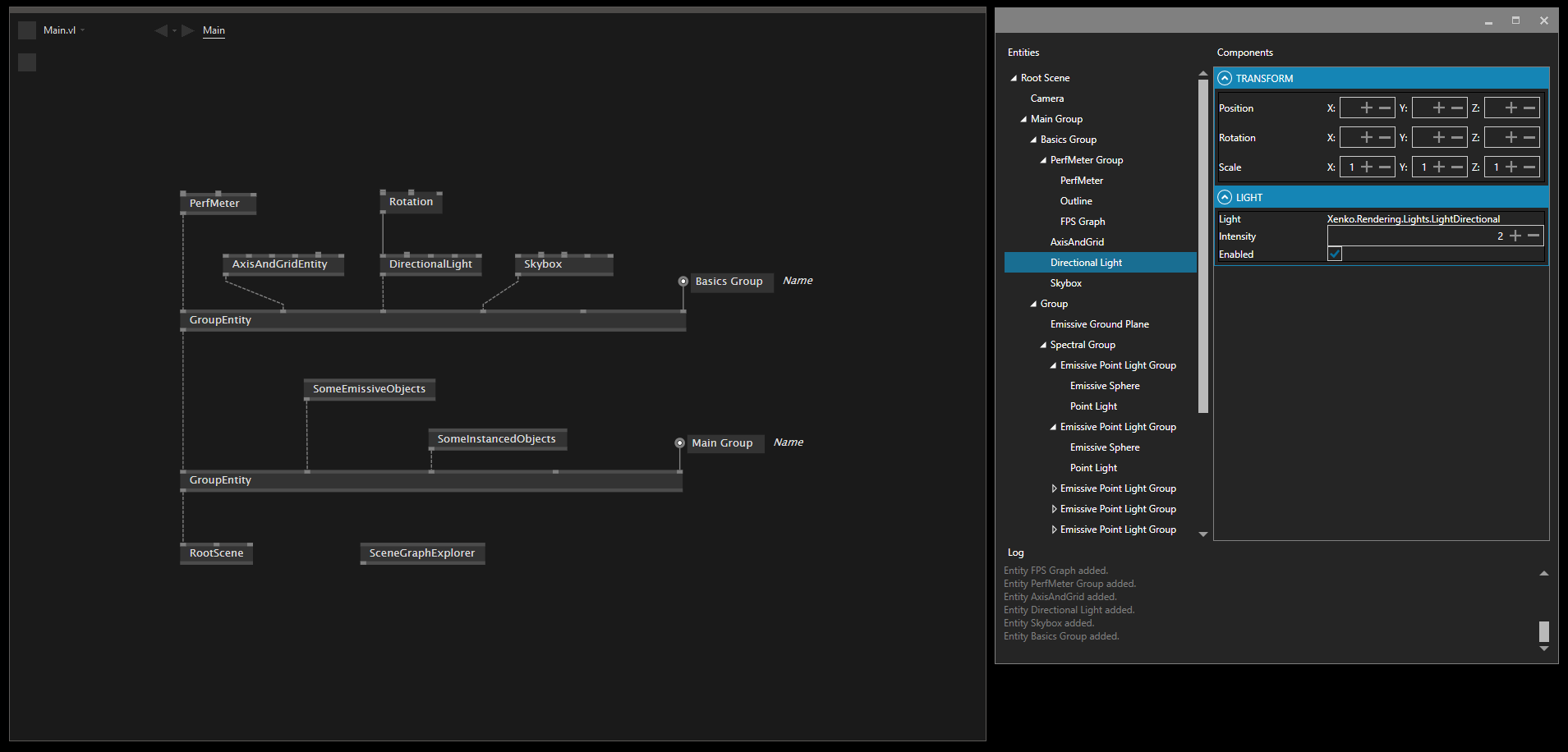
The scene graph is the fundamental data structure of the 3d engine. It contains the entities and scenes of your application. Most engines use a tree view to visualize and work with it. In vvvv, we have “Group” nodes to build the parent-child relations of entities.
For convenience, every group and entity got a transformation and name input. The name becomes handy for finding and accessing certain entities later programmatically or just for getting an overview. It also shows up in the tooltip.
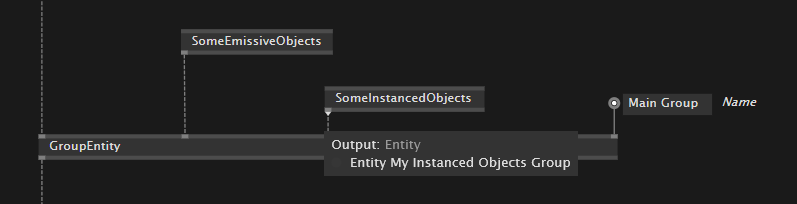
Scene Graph Explorer
The scene graph can become large and complex quite quickly. Especially when you are a brave patcher and you use sub-patches to stay organized. Sometimes you want an overview of the whole tree structure and see basic properties (at runtime, of course!). Luckily there was an older project for Xenko that traverses the entity tree and visualizes its components and properties.
We updated it to the latest Xenko version and imported it as a debug helper.
Materials
If you look at the options and properties of a material in Xenko it’s quite complex and some features require expert knowledge. To make things quick and easy, we made a few simple nodes to cover the basics.


We’ll also add texture-based versions of them and for more complex setups, you can always design the material in Game Studio and import it.
Runtime Asset Loading
For almost every project you have to import content. Be it images, videos, models or just text files. This sounds trivial at first, but as you come closer to deployment, it gets more tricky to have everything at the right place. Even more so, with the new executable export in vvvv gamma.
Game engines usually solve it like this: Resource files like models, textures, etc. get imported via the editor and compiled to runtime assets. These asset files get placed next to the executable on compilation. This works well for static assets, but for rapid prototyping and changes at runtime, we need something more flexible. So we took the Xenko asset builder and adapted it to work at runtime. This allows for importing and building assets while the application is running.
File Assets
Load single resource files directly from disk, aka FileTexture. Good thing is, this works together with Xenko’s asset database and caches already loaded files. So everything is pooled by default.

Load Project
That’s a nice one, you can create a Xenko project in Game Studio, work on Assets, Scenes, Prefabs, etc and import everything at once with the LoadProject node. It even updates on save!
Modify Imported Entities
Since we work directly with Xenko’s data types, imported entities are in no way different from patched ones. You can access and modify them in the same way:
Shaders
vvvv is known for treating shaders first class. The Xenko team seemed to have a similar attitude. They created their own shader language called XKSL. It is a superset of HLSL, so you can paste shader code from vvvv into an xksl file.
However, there is much more. They added quite unique features that make writing shaders easy, fast and clean. If that wasn’t enough, you can compose shaders with other shaders at runtime and avoid an explosion of shader permutations.
TextureFX
The well known TextureFX node-set in vvvv beta makes working with textures easy and fun. Of course, we want to have the same experience in vvvv gamma. But, with preview in the tooltip! There you go:

ShaderFX + FieldTrip
Visual shader programming with nodes? Yes, please! The composition feature of XKSL makes this easier than expected. Turns out, the Xenko team was working on something similar which made it relatively easy to build a node-set around it.
To test these nodes, we had the pleasure to have Kyle McLean in our office for some days and worked with him on porting FieldTrip nodes to VL.Xenko.
FieldTrip is a modular shader library Kyle McLean created for vvvv beta. It includes raymarching and general tools to work with scalar fields and vector fields on the GPU.
We ended up with a working prototype, as you can see in this video from the vvvv berlin meetup:
StreamOut Instancer
Since Xenko has no native instancing for their material shaders yet, we tried to use stream out aka transform feedback to transform a mesh multiple times and build one big vertex buffer that works with the Xenko material pipeline. The node works nicely and takes a Mesh, a material, and the instance transformations. You can easily draw a few thousand instances with it. The header image was mostly done with it.

Profiler
The bigger your project gets, the more important it is to know how well your shaders perform. Thanks to Xenko’s profiler infrastructure we can give every shader a profiler key and see it listed in the GPU page:


Next Up
There are still some topics left in order to make VL.Xenko as convenient as we like it to be.
Multiple Windows
One major feature that vvvv beta does exceptionally well is working with multiple windows. Games are usually focused on one output window. In order to get this to work, we have to find a solid way to instantiate multiple windows in Xenko and render content into them. This requires some coding behind the scenes. We are planning to get this done by early 2020.
One-Click Installation
At the moment one still needs Visual Studio to set up a VL.Xenko project. This should, of course, be just a one-click package installation as we have it with other VL libraries. Initial tests went well and we are confident that this will work out just fine.
Rename to Stride
Because of legal reasons about the trademark, Xenko has to do a re-branding and will be called Stride soon. We'll of course follow along and will rename the library to VL.Stride.

As much as we want everyone to try it, it won’t make much sense to share the library in its current state. The setup process needs developer knowledge and a few main features are still missing. But stay tuned for more on that!
If you want to know more about something specific or have any remarks or requests, don't hesitate to leave a comment below.
That’s it for now, looking forward to NODE20 and more exciting patches in 2020.
yours,
devvvvs
Alles neu!
With vvvv beta we clearly missed quite some opportunities by not providing a clear getting started path for newcomers. Only 15(!) years after launch we added a Getting Started page. Around the same time we added some built-in tutorials you'd see on startup plus some links to documentation, forum and chat. But those would be gone forever once you decided to hide the welcome-patch on startup.
So this time around, we wanna try something different...
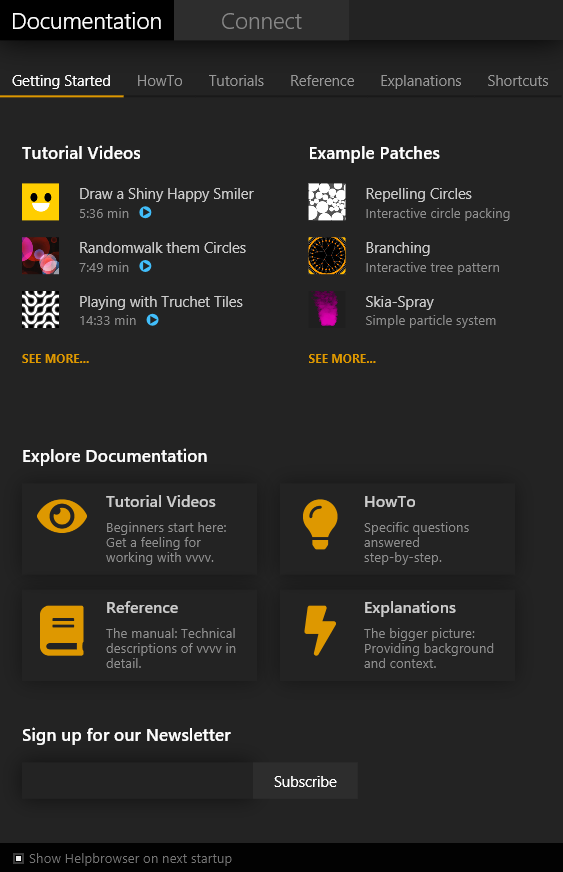
The screenshot shows the current status of the helpbrowser as it comes with the latest previews of vvvv gamma 2019.2. It will open by default for every new user and offer a series of tutorials and example patches and encourage to explore the documentation. Obviously we now need to provide many more tutorials, examples and add more documentation, but this provides a structure to fill.
For now, the most useful pages of the documentation are HowTo and Shortcuts which are both searchable. And note that the content of the HowTo tab is dynamically sourced from all packages you have installed! Most other links in the browser go to external sources (youtube, graybook) but we're planning to someday include more content in the browser directly.
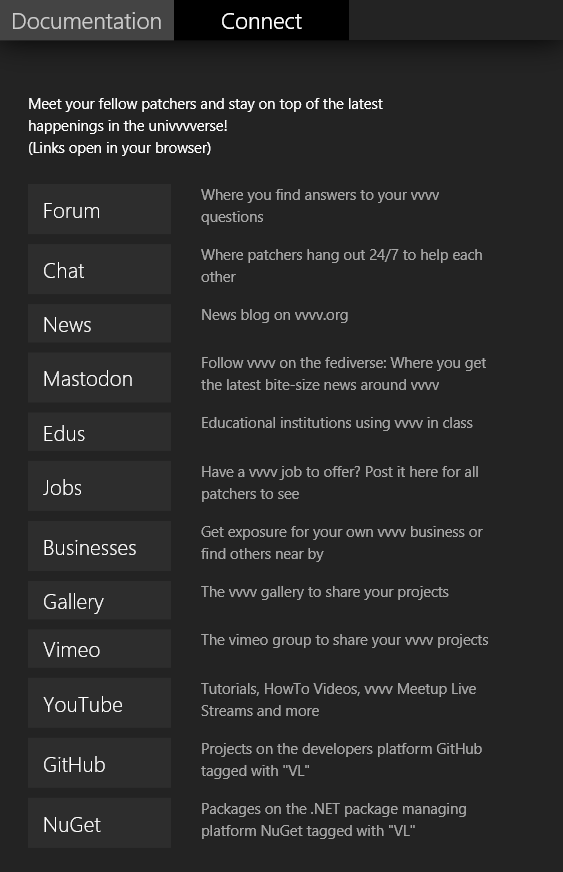
Connect
The second tab is still rather dry for now but at least is supposed to give new users an overview of the most important entrypoints that are available to our univvvverse. Later we'll want to make this tab a bit more lively by e.g. showing some of the latest live content of those entrypoints. Think latest forum topics, news, screenshots of the day...
With the release of vvvv gamma 2019.2 preview it's now finally possible to create standalone applications out of any vvvv patch.
The steps to create an application are as simple as this:
- Download and install vvvv gamma 2019.2 preview
- Open the patch you wanna have as an executable
- Open the application exporter by pressing F9
- Press export and voila you have an executable which runs on any Windows 10 machine
To learn how to deal with referenced assets, read Exporting Applications in the gray book.
So please try it out with your projects and report any findings in the forums or the chat.
anonymous user login

Shoutbox
~3d ago
~12d ago
~12d ago
~23d ago
~24d ago
~26d ago
~26d ago
~1mth ago
~1mth ago
~1mth ago