
Blog
Blog-posts are sorted by the tags you see below. You can filter the listing by checking/unchecking individual tags. Doubleclick or Shift-click a tag to see only its entries. For more informations see: About the Blog.


Here goes!
We have a candidate for our upcoming release:
Here are some of the highlights:
- Improved patching performance in large projects
- A new Hamburger menu with easy access to settings and themes
- Support for editor extensions
- Language refinements: This node and explicit type parameters
- Video: Support for the effortless playback of a wide range of formats, see Video Playback
Skia 2d rendering:
- Now fully GPU accelerated
- Skia to Stride now works on all GPUs
- ImagePlayer to play image sequences as image
Stride 3d rendering:
- TextureFX: a vast collection of easy to use nodes for applying visual effects to textures
- Pipet, MeshSplit, Texture and Buffer nodes for VL.Stride
- ImagePlayer to play image sequences as texture
- New PostFX: Fog and Outline
- ShaderFX node factory to easily write composable shader snippets
- Materials can be extended with custom shaders
For full details of what's new, please consult the Change Log.
So please test and report your findings. If we don't find any complete show-stoppers within the next days, this is going to be it!
Here goes!
Available in experimental form since a while already, vvvv gamma finally will ship proper stable video playback options with upcoming 2021.4. So here is what we've got for you:
Video files
Typing "video" in the nodebrowser shows the VL.Video.MediaFoundation nuget. Reference it to get these nodes for video playback:
- VideoPlayer (Stride): returns a texture for VL.Stride
- VideoPlayer (Skia): returns an image for VL.Skia
Both play the same wide range of containers and formats and some more can be added by installing the Mediafoundation codec pack.
Image Sequences
For the playback of image sequences, find the following nodes shipping with the respective nugets:
- ImagePlayer (Stride) and ImagePlayer (FrameBased Stride) for VL.Stride
- ImagePlayer (Skia) and ImagePlayer (FrameBased Skia) for VL.Skia
Check their help patches for details on supported formats and some more fine-print.
For arguments regarding when to use the VideoPlayer vs. the ImagePlayers nodes, see the new chapter on video playback in the gray book.
Network synchronization
Yes, please! Using the ImagePlayer nodes, vvvv also offers to have them play in sync on multiple PCs.
Available for testing now in latest 2021.4 previews.

Since the first public preview release in summer 2020, we've made steady progress and released many updates based on feedback and bug reports. In case you didn't follow the daily changes, this blog post highlights additions you might have missed and are worth checking out.
Help and Example Patches
First and foremost, we added loads of new help and example patches. It is already a nicely browsable list in the help browser, with more in development:

Model, Mesh, Material and Texture Tooltips
A core feature of vvvv is to have a live preview of your data. And since you can patch your own tooltips to do exactly that, we patched previews for Materials, Models, Meshes, and Textures. More to come!
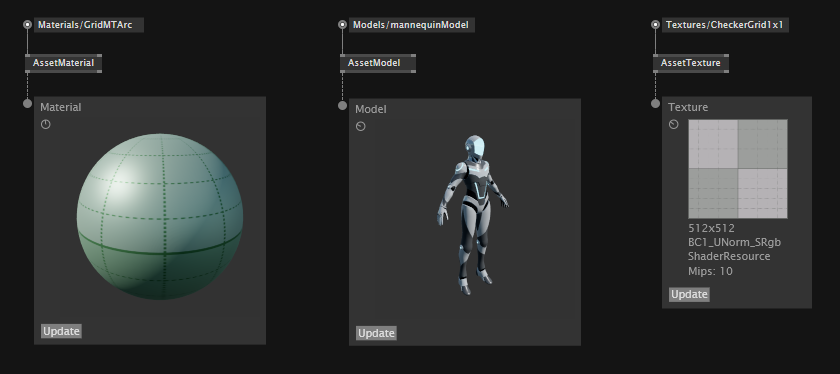
Material Cleanup
A Material describes the rendering pipeline. This is very fundamental and after working with the first iteration for a while we found some improvements:
We reduced the number of base nodes and added easier building blocks to customize a material. There are help patches for most of these, check the help browser and the material category in the node browser. It basically mirrors the Stride documentation.
Simpler Data Input
The parameters of a material are GPU values, either float or color. For the GPU a color is just a vector with 4 components, so we now have inputs of type GPU<Float32> and GPU<Vector4>. We simplified the node-set in a way that you can use a single value, a texture, or any dynamic GPU value. There are also nodes to input different values per instance. The reworked nodes are internally built with ShaderFX. If you are interested, have a look inside the new nodes to get an idea of how you can build your own.

Async Compilation and Caching
Compiling complex materials takes a while because there are often several shader stages involved. Stride has a mechanism to compile a material in the background and cache the compiled shaders on disc. So the next time the same material is used, it loads almost instantly. So when you see a geometry blinking green, it means that the material is compiling in the background and will be saved to disc. If it is blinking red, the material has an error.
In practice, this means a patch loads much faster the next time you open it.
Virtual Reality
Rendering any scene into a VR headset is now straightforward, just have a look at the new help patch.

Aspect Ratio and Units
When you build on-screen displays you often need pixel or device-independent units (DIP). And if images are involved, they should keep the same aspect as they are stored. For these tasks, we now have new nodes that calculate these spaces for you. And the QuadRenderer got aspect ratio modes that depend on the connected texture:

Perspective Look at Rectangle
Simulating a perspective that behaves like looking through a window is an important tool. It allows you to create cameras for interesting things like virtual productions and head tracking. There is also a help patch to get you started.

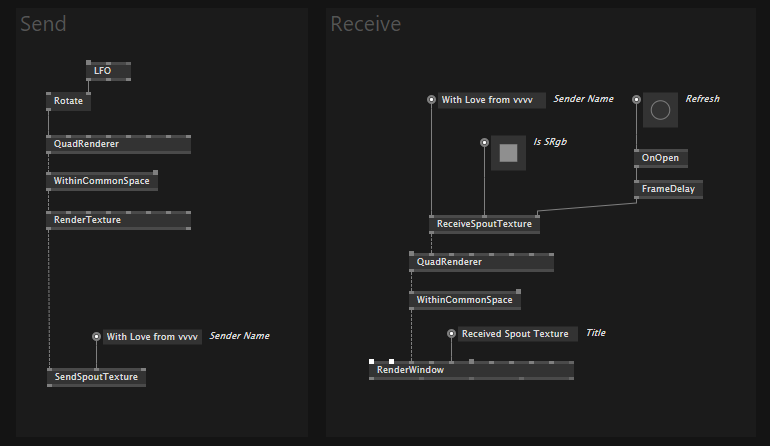
Spout and Shared Texture
You can now share textures with other software using Spout or shared textures. Spout 2 support is also planned for the next release.
Patch Script
This workflow is for advanced users. It allows you to attach a patch as a sync script to an entity. That's a common workflow in ECS-based game engines and you can find many tutorials on youtube that use this design pattern.

In some cases, this has an advantage over just placing an entity node in a patch and building logic around it. For example, you can retrieve your attached script-patch from the entity somewhere else and call operations on it. You can check out a use case in the forum thread How can I modify a material without changing the original node?. There is a help patch as well.
Light Shafts
Thanks to the efforts of TremensS we got help patches that explain how to use LightShafts:

Video Tutorials
So far, we released two video tutorials:
Other Bits and Pieces
Move to Official Stride
After we’ve done many pull requests that fix bugs and add features that we need, we switched to the official Stride release nuget packages. This allows for an easy workflow when you load a Stride project since the version now matches to what the Stride installer downloads by default.
Fullscreen
Got some fixes, however, there is one known bug. In a multiscreen setup, when the window is too far on the right on one screen, it goes fullscreen on the next screen to the right. We’ll try to fix this in the upcoming releases, of course.
TextureWriter
Easy node to write textures to disc. You can use this in combination with the incremental main loop mode to export animations.
General Advice
Most high-level nodes, like Sphere, DirectionalLight, and so on, are simple patches made from more fundamental building blocks. A good way to think about them is to see them as a "default setup" and not a finished black box.
So if you miss a feature, or a node does too much, look inside and copy parts of it, or the whole definition into your personal library document to customize it.
We also try to stay as close as possible to the Stride documentation. So if you are looking for more info on a certain feature, it is always worth peeking into it.
Contributing
If you have a useful addition or you want to contribute in any other way, you are welcome to fork VL.Stride on GitHub and make a pull request. We are always happy about new help and example patches.
What's Next?
As a first step we want to improve:
- Input event handling (Mouse, Keyboard, Touch, Gestures)
- TextureFX
- GPU resources handling, aka buffers and textures
We'll also add these features:
- Entity picking
- Load Model Animations
- Load Model Materials
And we are also working together with the FUSE team on more advanced rendering node libraries built on top of VL.Stride.

Looking forward to seeing what you will create with it! -> Latest download is always here.
yours,
devvvvs
P.S.: The gallery of VL.Stride impressions also got some new additions.

Here we are now!
Getting vvvv gamma 2021.3 out, including the 3d engine VL.Stride, was the last big milestone to bring vvvv gamma up to par with (and far beyond) vvvv beta. One could think this would give us a bit of a break but far from. The next big mountain we're looking forward to climb is right in front of us and it is called: .NET5.
.NET is the framework that vvvv gamma is built on and version 5 was just released a few months ago. It comes with a lot of goodies but also a bit of work for us to adopt to it. So moving vvvv gamma to .NET5 is our next big priority which we plan to ship with 2021.5 towards the end of the year.
Before that, we're planning to release 2021.4 around the end of May in which we take a lot of preparational steps towards .NET5 but don't do the switch yet. Like this, we're hoping to not delay the next release for too long and already get some nice things out earlier.
So here is a first attempt at a public roadmap. Let's see how that goes...
Planned for vvvv gamma 2021.4
Library
Since we now have the most common things in place, we're going into a cleanup phase here with these priorities:
- Update to the latest NuGet API to allow you to use all the latest nugets
- Streamline VL.CoreLib by moving parts that are not really "Core" or "Windows only" into separate libraries and making them open source
- Get more of the most significant nugets stable, starting with Audio and Video
A big focus will also be on further improving VL.Stride:
- Improve Mouse, Keyboard, Touch nodes
- Rework Buffer and Texture nodes
- Allow for simple shader creation
- Add a clean set of TextureFX
- Add Entity Picking
UI/UX
We all have a lot of wishes in this area but tackling some of the bigger things here will still have to wait for the switch to .NET5. For now, we're concentrating on the following:
- Tackle the existing performance issues that you face when handling larger projects
- Improving the workflow for setting the data type of pads
- Providing a UI for the Settings
Language
While there are many ideas how to improve the language with new features, we will need to focus on a cleanup of an already shipped language feature: with this release, we'll fix some bits regarding generic type definitions.
Planning a release ahead is difficult and can be disappointing when you mostly see the things that again didn't make it to the shortlist. We've also already laid out 2021.5 and 2021.6 internally but don't yet feel comfortable publishing them yet. The move to .NET5 still has a few unknowns that we want to better understand before we talk more about it. Therefore in the meantime, we only offer a few general notes about our further agenda. To be reviewed after each major release.
Apart from the upcoming major releases, we're committed to regular smaller bug-fix releases to the current 2021.3.x branch.
As always, you can follow our development by test-driving the daily previews.
Here we go!
We have a candidate for our upcoming release:
This is going to be the first stable release including the huge shiny new 3d rendering library we created based on the Stride Engine!
For more details of what's new, please consult the Change Log.
So please test and report your findings. If we don't find any complete show-stoppers within the next days, this is going to be it!
Here is,
another addition to the series of things that took too long. But then they also say that it is never too late... VL was shipping with OSC and TUIO nodes from the beginning, but frankly, they were a bit cumbersome to use. So here is a new take on working with those two ubiquitous protocols:
OSC
Receiving OSC messages
To receive OSC messages you need to place an OSCServer node which you configure to the IP and Port you want to listen on. Immediately it will show you if it is receiving OSC messages at all on the Data Preview output.
Then use OSCReceiver nodes to listen to specific addresses. Either specify the address manually or, hit the "Learn" input to make the node listen to the address of the first OSC message it now receives.
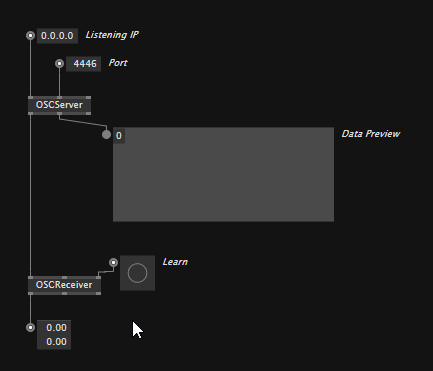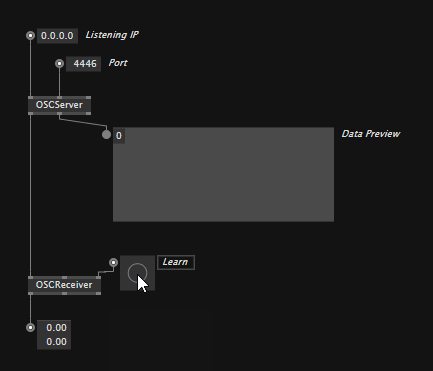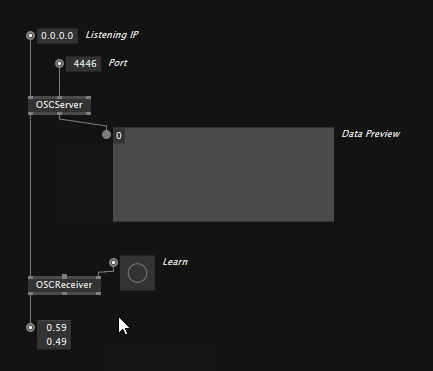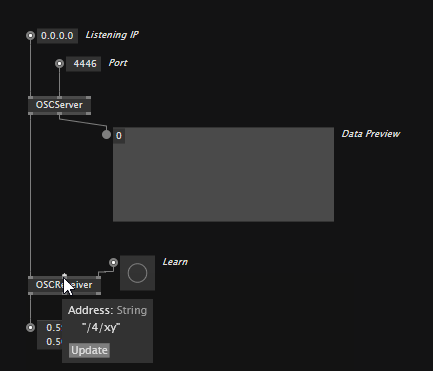
Note, that the OSCReceiver is generic, meaning it'll connect to whatever datatype you want to receive. Supported typetags are:
- i: Integer32, h: Integer64
- f: Float32, d: Float64
- s: String, c: Char
- r: RGBA color
- b: blob byte[]
- T: true, F: false
In case of multiple floats, you can also directly receive them as vectors. And this works on spreads of the above types and even on tuples, in case you're receiving a message consisting of multiple different types.

Sending OSC messages
To send OSC messages you first need an OSCClient which you configure with a ServerIP and Port. Then you're using SendMessage nodes to specify the OSC address and arguments to send. Again note that the "Arguments" input is generic, so you can send any of the above types, spreads of those and even tuples combining different types!
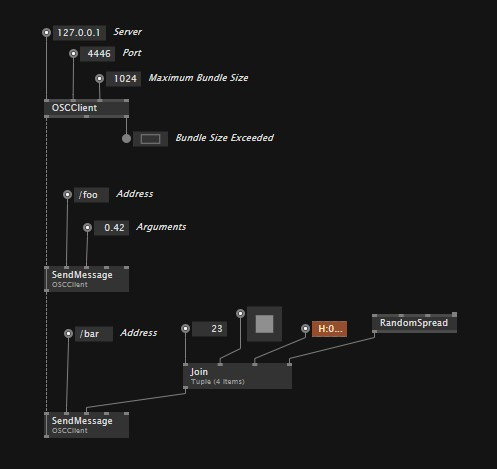
By default, vvvv is collecting all the data you send and sends it out in bundles per frame. For optimal usage of UDP datagram size (depending on your network) you can even specify the maximum bundle size on the OSCClient node.
These are the basics. There are a couple of more things which are demonstrated in the howto patches!
TUIO
Receiving TUIO data
For receiving TUIO data you're using a TUIOClient which you configure to the IP and Port you want to listen on. The client already returns a spread of cursors, objects and blobs that you can readily access.

Sending TUIO data
For sending TUIO data you're using a TUIOTracker node which you configure with a ServerIP and Port. Then you give it a spread of cursors, objects and blobs to send out.
Available for testing now, in latest 2020.3 previews!
Hello everyone,
Introduction
I'd like to give you an update on the toolkit front, that vvvv has always been. While vvvv beta can be described as a dynamic system, mutating while you mold your patches, vvvv gamma and its workhorse VL are of a different kind. With VL we embraced features like
- static typing with its ability to detect errors early,
- .Net DLL import opening a universe of possibilities,
- user-defined data types that interplay with those defined by others,
- compilation with its ability to export an app as an executable...
In short, we embraced robust software developing strategies that at first seem to contradict the idea of a playful development toolkit that allows you to mold your app. We went for compiled patches, running, and hot-swapping them while you are building them.
But we envisioned vvvv to be both
- the playful toolkit you fell in love with
- combined with the promises of a compiled language
While my last blog post was about the language, let's focus on the toolkit this time.
Toolkit
Let's have a look at some features that allow you to interact with the VL runtime, the system that runs your patch while it allows you to edit it. The features here empower you to enrich the patching experience. We understand that these improvements need to "trickle up" into the libraries and only thereafter will have an effect for all users.
So the following is probably mostly interesting for advanced user and library developers.
Tracking Selection within the Patch Editor
You now can react to a selection within the patch editor. The more libraries do this the more playful the environment gets. We still have to figure out all the use cases, but here is a list of what's possible already
- separate the core functionality from its Editor UI. Imagine a TimeLine node that is decoupled from the timeline editor.
- an Inspector for nodes or pads
- a Preview like this:

- even the help browser itself uses the feature to provide help for the selected node.
And there is more:
You can get a Live Element for a certain Pin or Pad.
- Copy the permanent identity of the element into the clipboard by CTRL-SHIFT-I (I stands for Identity).
- GetLiveDataHubForSerializedID hands you the pin or pad.
useful for the cases where you want to always inspect a specific pin or pad of some patch. This can be helpful for debugging.
Let the Patch Editor navigate to a Patch
When a Skia Renderer is your active window, Ctrl-^ let's you jump to the patch in which it is used. This is handy when you opened a bunch of help patches and you want to see the help patch that is responsible for the output.
You can use the node ShowPatchOfNode to do the same trick.
Tooltips for your own data type
Here you can see a custom tooltip for a user patched type "Person".

You now can patch your own tooltip with RegisterViewer. This way the patching experience will be so much more fun. We're in the process of adding more and more viewers for our types.
Runtime Warnings
Up to now, we had
- Red elements: Static errors. (E.g. a node that can't be found) These errors make the compiler ignore certain parts in your program as they are currently in development. The rest still runs. (Something what C# and others just can't)
- Orange socks on links: Static warnings, potential problems. Something to look at when searching for a bug.
- Pink nodes: Runtime Errors. A problem that only got detected during runtime and which is such a big problem suddenly that the system can't work as planned. Some patches don't run as planned. There are different ways how to handle these, pointing you at problems at runtime, but they can be painful.
And now we introduce to you:
- Orange nodes, Runtime Warnings: They show you a problem at runtime. But it doesn't harm your system as pink nodes do. Orange nodes are runtime warnings. Library developers can put warnings on their nodes in order to communicate to the user that something is slightly off.
You can try it yourself by using the Warn or the Warn (Reactive) node.

The warning will not only show up on the Warn node, but also on the applications of your patch.
S&R nodes
Sometimes it's just convenient to be able to send data from one patch to another without the need of feeding the data via pins. We now have send and receive nodes, like known from beta.
Features:
- The channel can be anything. It doesn't have to be a string.
- They have several warnings. E.g. for when none or many senders are on a channel that a receiver is listening to.
Descriptive Tree patching
Some libraries focus on a simple idea:
Let the user build an object graph that describes what he wants in a declarative manner and the library will do the hard work to follow that description.

Examples for this approach are
- VL.Stride
- VL.Elementa
- to some extend VL.Skia
VL.Stride and VL.Elementa have in common that they focus on a very certain type of object graph: A tree made out of entities and components.
Libraries like these can now talk to the user and enforce the user to not build any kind of graph, but a tree-shaped graph (where one child doesn't have many parents).
VL.Stride uses TreeNodeParentManagers, Warn nodes and S&R nodes internally to the deliver this feature:

You'll very soon be able to inspect those patches.
Help patches to all those topics will show up in the CoreLib API section (at the bottom of the listing).
We hope you'll enjoy these ways of integrating with the development env.
Thank you and we'll see you soon!
yours devvvvs
Did you ever wonder what the first things were, that the cool kids in the VL.Stride EarlyAccess program created with the new 3d rendering engine for vvvv gamma?
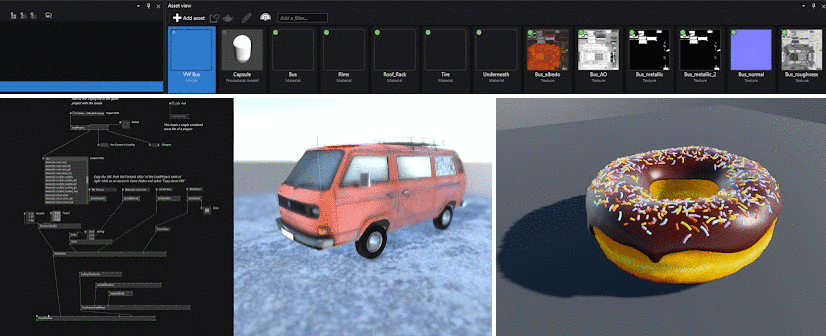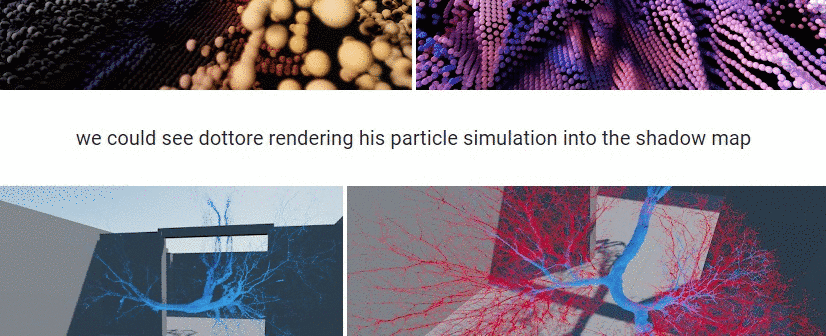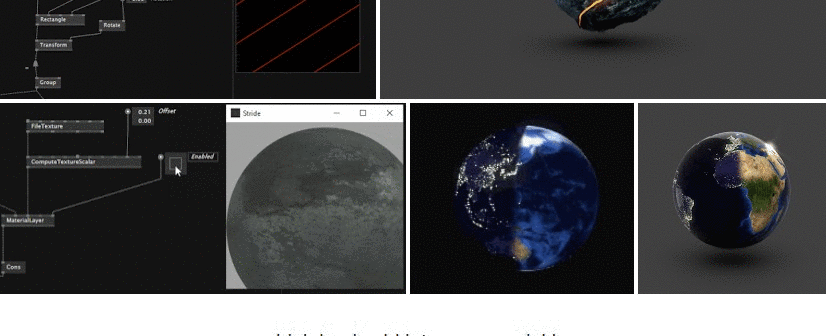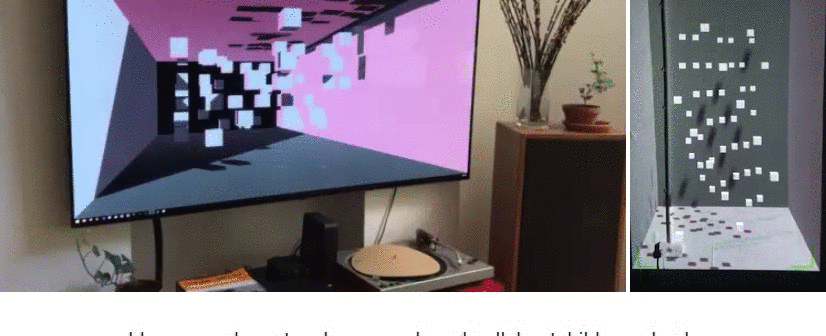
It's been only a few weeks, but stunning pixel combinations got posted into our early access chat room.
And we collected them in a gallery for you:
A big THANK YOU to everyone involved!
We can't wait to see what you will create with it. And don't miss the workshops at NODE20 if you want to learn how to use it.
We are looking forward to the public release as much as you do,
yours devvvvs

In a quest to get more basic things working out of the box with VL (ie. using vvvv beta>=40 or the all-new vvvv gamma), we took on to support your favorite depth cameras. Most of the cameras and their APIs share basically the same features as a baseline and then some of them have a few extra features. This means that using them in vvvv works mostly the same for all of them.
You have the main device node that you connect ColorImage, DepthImage, PointCloud, Skeleton,... nodes to, to get the desired info out of them. See the help patches coming with the packs for details.

Here is a list and comparison of all available depth cameras with links to the respective packs on nuget.org. To learn how to use nuget packs with vvvv please watch HowTo use Nugets.
Kinect
The original Microsoft Kinect or the XBOX 360 that was released a bit later.
Get the VL pack on nuget.org.
Created with support by chaupow.
Pros
|
Cons
|
Kinect v2
The second version of the Microsoft Kinect.
Get the VL pack on nuget.org.
Created with support by ravazquez.
Pros
|
Cons
|
Azure Kinect
The third version. AzureKinect.
Get the VL pack on nuget.org.
Get the VL pack for skeleton tracking on nuget.org.
Pros
|
Cons
|
Orbbec Astra
Orbbec Astra.
Get the VL pack on nuget.org.
Pros
|
Cons
|
Intel RealSense
Intel RealSense.
Get the VL pack on nuget.org.
Pros
|
Cons
|
Nuitrack API
Nuitrack is a piece software that works with all of the above cameras and provides skeleton, hand and face tracking.
Get the VL pack on nuget.org.
Created with support by ravazquez.
Pros
|
Cons
|
Leap Motion Controller
The Leap Motion Controller device provides hand and finger tracking.
Get the VL pack on nuget.org.
Pros
|
Cons |
Please help us improve this list of pros and cons. Know any other or disagree with some mentioned, please add them in the comments! This could eventually grow into a page of the gray book.
Evvvveryone,
is happy, that we're finally looking at a candidate for beta40, which will ship with the latest and may i say greatest integration of VL to date that is 2020.1.4!
For the latest changes in VL, please consult the vvvv gamma series 2020.1.X changelog.
Most notably this gives you access to all the latest goodies that are popping up as .NET nugets lately. Yes, we're still missing a convenient overview of those, but meanwhile a search for VL on .nuget.org gives you an idea. Still wondering how to use those? Watch this tutorial on How to use Nugets to find out.
So please test this against your current projects. Make sure that everything is running as expected. If not, please leave a comment below or let us know in the forum.
Download
vvvv beta40 x64 RC2
vvvv beta40 x86 RC2
Changelog for Candidates
RC2
- now using latest RCPSharp, allowing the Rabbit again to listen on 0.0.0.0
anonymous user login

Shoutbox
~6d ago
~6d ago
~7d ago
~20d ago
~1mth ago
~1mth ago
~1mth ago
~1mth ago
~1mth ago
~1mth ago