
Blog
Blog-posts are sorted by the tags you see below. You can filter the listing by checking/unchecking individual tags. Doubleclick or Shift-click a tag to see only its entries. For more informations see: About the Blog.

Finally,
we have regular expressions in vl. What the? Here is the gist:
via docs.microsoft
vvvv beta comes with the RegExpr (String) which is quite handy but doesn't cover all cases. vux provides a RegExpr (String Replace) via the addonpack, which adds the "replace" case, but there is more. So let's see what we got in shop for vvvv gamma:
Pattern matching
The simplest case: Just figure out if a given string matches a given pattern:

Replacing by pattern
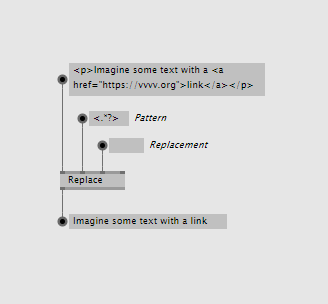
Sometimes a simple replace by string is not enough. See this example where we're stripping a string of all occurences of html-tags, ie. replacing them with nothing.
Splitting by pattern
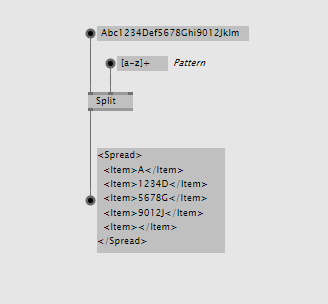
Sometimes a split by string is not enough. See this example where we're splitting a string by any multiple occurances of lowercase letters:
Finding occurences by pattern
Find all substrings that match a given pattern. Imagine a string that contains many dates written in the format "Month Day, Year" and you want to get all of those:

RegexOptions
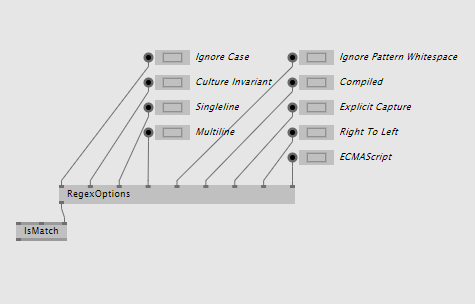
The last pin on all of the above nodes is the Options enum pin. Since this enum allows multiple selections (ie. a bitwise combination of its member values), there is a RegexOptions node that allows you to set multiple of the options at the same time:
And more
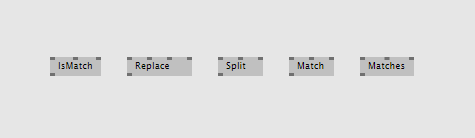
The above should cover most typical usecases. But regular expressions can do even more. Luckily with vl you're not restricted to what we decide to provide for you, but you have direct access to the full set of functionality .NET regular expressions offer. For example there are situations where you want to use the static operations that .NET provides instead of the process nodes shown above. If so, simply choose "Advanced" in the nodebrowser and, navigate to the "Regex" type and choose the static operations from there...
Available for testing in latest alphas now!
Holy patchers!
To answer the often contemplated question of "Where the hell is this all going?" we first have to establish that vvvv is different things for different people. Let's have a look at some of these different perspectives:
■ vvvv - a generative designers best friend
■ vvvv - a data visualizers wonder weapon
■ vvvv - an interaction designer's magic wand
■ vvvv - the multiscreen solution
■ vvvv - physical computing covered
■ vvvv - a projectionmapper's dream
■ vvvv - rapid prototyping on steroids
■ vvvv - your procedural lighting desk
■ vvvv - computervision for everyone
■ vvvv - stage? show? control!
■ vvvv - fish feeding for the lazy
■ vvvv - L.A.S.E.R zzzz!1!!
That's all?, we hear you say...and you mumble on, but can I please has:
■ vvvv - a tool for machines to learn
■ vvvv - easy logic for gamers
■ vvvv - visual scripting done right
■ vvvv - klickklickklick your mobile app
■ vvvv - the no-brainer IOT toolbox
■ vvvv - the final webdev solution
■ vvvv - an admin's batching buddy
■ vvvv - robots dig this
■ vvvv - no controller too micro
■ vvvv - from sound to noise in one patch
■ vvvv - any shaders of gray
■ vvvv - scratch that: kids taken seriously
Well, vl, vl, we hear ya.. and that's exactly why at the heart of it all, we have always been, and will continue to work on:
■ vvvv - a multipurpose toolkit
Introducing vvvv gamma
When we started working on VL, we never thought about creating anything different than vvvv. We had our issues with vvvv and wanted to solve those. But mostly we loved it and wanted to keep the good things we still enjoy about it. Essentially we set out to rewrite vvvv to make it better, nothing more.
So it is our great pleasure that we can finally annouce the impending release of what we've so far been referring to as "VL standalone":

For a start, vvvv gamma will focus on 3 main scenarios:
- 2d interactive motion graphics using VL.Skia
- computervision using VL.OpenCV
- controlling devices, ie. everything IO (Midi, UDP, OSC, RCP, HTTP...)
Frankly it will be gorgeous and above all shine through the following features:
|
|
So beta vs. gamma, really?
Nope, don't think vs., we prefer to think ♥!
Here is how to read this: Over the past years we've been R&D'ing a next generation visual programming language that we dubbed: VL. And we still call it that: VL is a programming language, just like c#, that now happens to power two of our products:
- vvvv 50betaX
- vvvv gamma 2019.X
While for vvvv beta, VL is just another language it supports, for vvvv gamma, VL is the core. As such, both beta and gamma will continue to profit as we progress with VL. We are well aware of the fact that gamma is not going to replace beta for everyone anytime soon. We're therefore commited to support both equally for the foreseeable future.
If you're interested in a few more details regarding how we'll be polishing vvvv gamma for its initial release, please head over to our roadmap.
What will gamma cost?
We're still working this out and will update you on licensing early next year.
Wait and what about Xenko/3d?
As we've previously reported from our lab, our initial efforts of integrating the Xenko 3d engine couldn't have gone much smoother. We have helped realize a complex multiuser VR project within just 4 months besides our research and now know that this is certainly the way for us to go forward. VL.Xenko will complete vvvv gamma to a fancypantsy interactive 3d authoring environment.
We're confident to be releasing an initial public version of VL.Xenko before 2019.Q4 and we have some ideas for a prerelease phase that we'll announce soon.
Thanks for using vvvv, thanks for your feedback on VL, thanks for your patience, thanks for the licenses you buy which makes this journey possible for all of us.
Have a nice holiday, get some rest, because 2019 will be the year of the vvvv desktop!
yours,
devvvvs.
This was long requested and it's finally here! Latest VVVV.OpenVR can use vive trackers without HMD (head mounted device). There is a dedicated pose output on the Poser (OpenVR) node and you can request the serial numbers of all connected devices.

Here is how to get started with high-performance 6DOF positional tracking for as little as $230 bucks. Minimum hardware requirement is one base station and one tracker. Although two base stations are recommended for much better tracking stability.
Features:
- No HMD required
- Use up to 62 trackers (64 minus base station and the null HMD)
- Trackers can be connected via USB cable or wireless via included USB dongle
- Trackers can be identified by their serial number
In order to get the trackers running without HMD you need to do the following steps:
1. Activate the 'null' driver
Find this file on your drive:
SteamDirectory\steamapps\common\SteamVR\drivers\null\resources\settings\default.vrsettings
change "enable" to "true".
Then open this file:
SteamDirectory\config\steamvr.vrsettingsAdd the following entries to the "steamvr" section:
"forcedDriver": "null",
"activateMultipleDrivers": "true",
SteamDirectory is usually C:\Program Files (x86)\Steam.
Also make sure to disable the "SteamVR Home" on startup. Otherwise it will try to render into the null HMD and consume 100% of one CPU core:

If SteamVR was running, close and restart it.
2. Connect the trackers
When SteamVR restarts, you can connect a tracker or controller without the HMD. Follow these instructions to pair the trackers ("Pair Tracker" is now "Pair Controller"): Pairing Vive Tracker
SteamVR should then look similar to this:
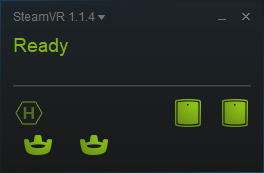
Note: The red “Not Ready” text can appear occasionally but that should be no problem if you are using the null driver.
Calibration
If you don't run the calibration process, the first found vive lighthouse base station will be the origin of the tracking space. If you can live with that you need to provide your own calibration matrix in vvvv and multiply it with the pose matrices coming out of the Poser node.
If you have the vive controllers you can run the room setup normally (no need for the HMD to be connected if you use the null driver).
You can also use the tracker as a controller for calibration, but you need to connect a simple circuit to the pogo pins to be able to activate the 'trigger' button during the calibration process.
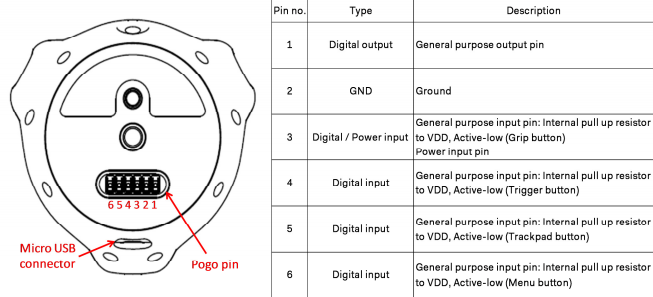
More detailed developer info on the pogo pins can be found here: Vive Tracker For Developers
You can download the new OpenVR pack here: VVVV.OpenVR
Open the demo patch 02_TrackersOnlyDemo.v4p in the VVVV.OpenVR\girlpower folder and enjoy tracking!
Big thanks to colorsound and u7angel for pushing.
VL: Xenko 3D Engine Update #3
Welcome back to the second sneak peek into our adventures with xenko. Together with MLF we've been busy patching the first project done entirely with vl and xenko: Ocean of Air. So far the combination works superbé, and you can experience that for yourself until the 20th of January, if you are in the London area. Alongside the project we explored the xenko code base and now that it's live, we can give you some more insights into our research.
In the last blog post we used predefined entities to set up a little scene graph. This time we will dig a little bit deeper.
Having primitive objects like Box, Sphere, Plane etc. is nice for casual patching and quickly visualizing something. But you will need more sophisticated objects for the final output of your project. What you want to do is designing your own objects that are specific to your use case.
Luckily, game engines have quite similar requirements and came up with a good solution, and they call it entity/component/system, short ECS, which is also the latest hype in Unity. Xenko has a good documentation page if you want to go into detail. But for now let's stay on topic and keep two things in mind:
- Entities are the nodes in the scene graph
- Components are the features/properties of an entity
We found two appealing ways to create custom entities that can also be combined with each other in any way that suits you. You can either patch them or design them in xenko's game studio using their prefab workflow. Here is a simple example for both cases:
1. Patching Entities
Let's look inside the BoxEntity from the last blog post:

As you can see, it adds a BoxComponent to the entity on Create (white) and exposes parameters like Color, Transformation, Enabled etc. as input pins on Update (gray). This is more or less an arbitrary choice of how the BoxEntity is designed and it will probably change a bit before it becomes official. The patch is also an example of how vl's process nodes work nicely together with the entity component model. Each instance of an entity or a component can be represented by a process node and connected with each other in an understandable way.
In the patch we saw the EmptyEntity node, which is a general entity object that contains nothing more than a TransformComponent, hence the transform input pin. To make something useful with it, we add more components (e.g. model, material, audio, physics etc.) to it. There are many of them and you can combine them as it suits your use case. The big advantage here is, that the components are able to interact with each other via the common parent entity and that the scene graph system automatically processes them in an optimized way. This is where it gets interesting!
Let's say we want the box from the patch above to emit a sound from its current position. In order to do that we only have to add a SpatialAudioComponent to the same entity as the box component:

Since the SpatialAudioComponent and the BoxComponent have a common parent entity they will share the same transformation. Also, if an entity has child entities, the children get transformed by the parent. We could use that feature to add an AxisEntity to our custom entity:

Again, there is no need to connect the input transformation to the AxisEntity since it gets added as a child to the main entity and gets transformed automatically.
Here is what a little scene could look like:


Let's add a second one and let them rotate in the scene to hear the spatial audio effect. Aaaaaand action! (works best with headphones):
2. Prefabs
There is also a super easy way to design custom entities in xenko's game studio and use them in your patch. Suppose we have a 3d model with animation and skinning imported and edited in game studio. All we have to do now is to create a prefab from it and give it a meaningful name:
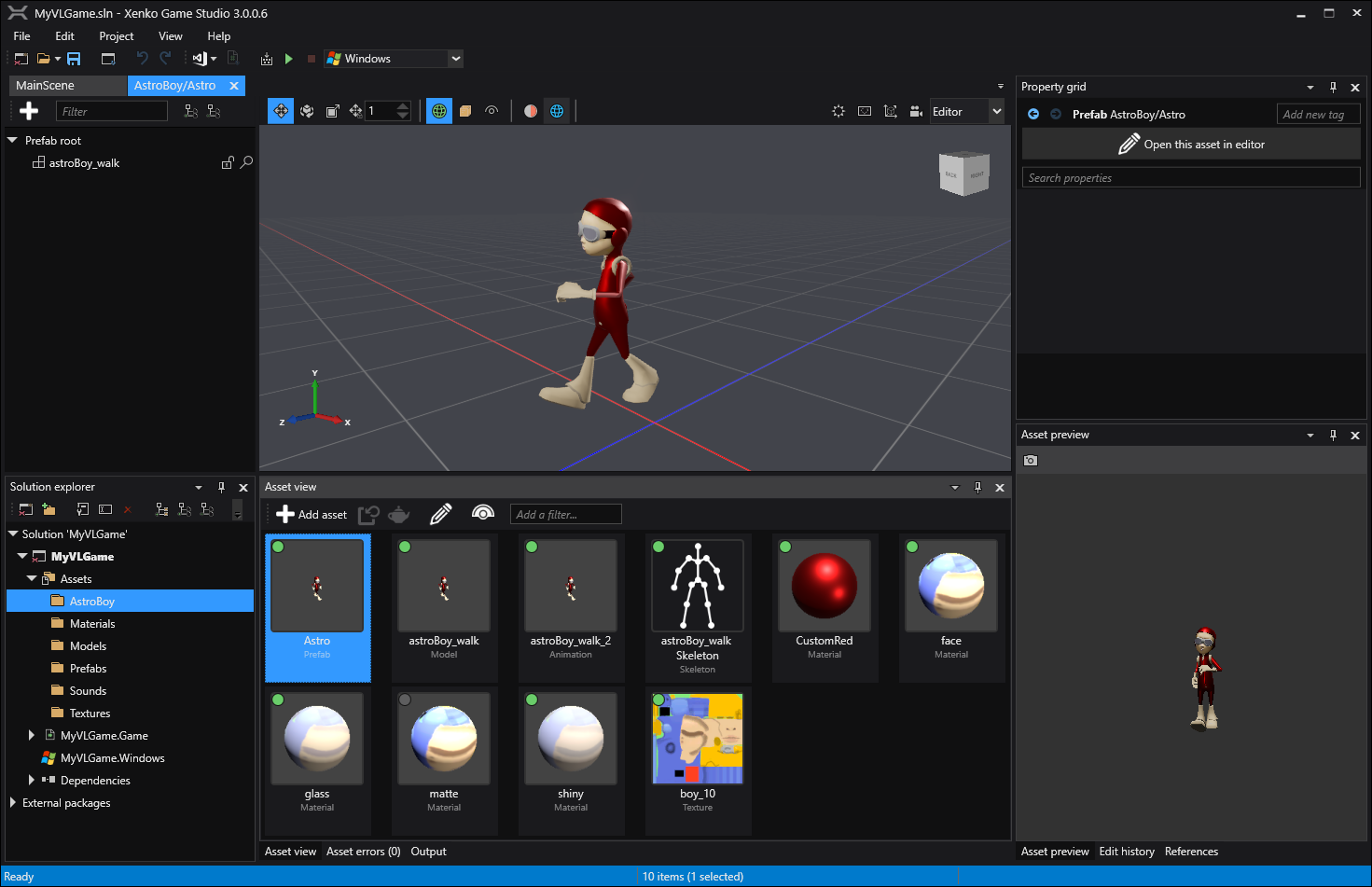
Learn more about xenko's prefab workflow here. Once we have that it's as simple as this to use it in your scene:

Ridiculous!
And finally we will start the walk animation:

Starting the animation is also patched in this case, but let's save that one for another post.
Conclusion
The entity component model of xenko works very well together with vl's process node feature. VL's automatic recompile and instant stateful hot reload allows to dynamically combine and configure entities and the scene graph in real-time while the application is running. You can combine different workflows with each other, simple primitives, custom patched entities or imported prefabs. There is no right or wrong, just build up the scene in a way that suits your way of thinking and the requirements of your project.
We still have only scratched the surface here, there is much more to come.
Yours,
devvvvs
Hello,
welcome the first update to our beloved 2D graphics library.
Since this summer's release quite a few things have happened.
The main focus was on covering every single aspect of the Skia's Paint (defines how everything looks like when rendered) and cleaning it up.
We would say it is now complete.
We've also introduced some special gems like Masks, Precompositions, Ellipsis and some more examples.
Never heard of Skia before? Check Skia on Wikipedia.
Read on.
Masking
You already were able to clip layers by rectangles or paths (ClipRect, ClipPath), now you can use any layer as a mask (as you know it from Photoshop), be it an image or very complicated layer pipeline. Welcome the Mask. It comes in two flavors: one uses a layer as a mask, another one just an image. The node has useful helpers which allow you to see how the mask looks like and where it is applied.

Precomposing
While researching for the masks we've stumbled upon Skia's superpower: we call it precomposing. Layers can be precomposed (leaving canvas unchanged) and then applied (grouped) with other layers. It's like having an extra render pass that works like a layer.
So now you've got two options: you can blur every single particle alone (by setting SetMaskFilter > Blur) or prepare all of them (precompose) and then blur the whole scene at once (by setting SetImageFilter > Blur).

In the screeshot above:
Left - every single circle is blurred alone, the background comes into play.
Right - the whole precomposition is blurred.
Ellipsis
Then we have these boring Ellipsis nod... nodes. They clip your text (left, right or center) by the number of letters or the width in units. Like this:

Paint completeness & cleanup
We've cleaned up the Paint a lot and now you can set or get any of its properties. Don't forget to turn on the "Advanced" filter of the NodeBrowser (like in the screenshot or just press TAB-key) to get the full power. SetFakeBoldText anyone?
In the Paint category:
- Processnodes (having an icon with two dots) are for setting properties (they start with Set)
- nodes with an empty box are for getting properties
- Processnodes without Set (like Stroke, Fill or FontAndParagraph) are convenient nodes setting several properties at once.

Examples and Demos
Don't forget to check the /examples folder of the package (your-vvvv-folder/lib/packs/VL.Skia.xxxx/).
There are also some updates to the /examples/demos, like the Slideshow.vl which let's you click through your-very-big-images asynchronously preloading them in the background.
Some more features:
- ImageEncoder
- ImageWriter
- SubpixelText property is on by default
- Pipet (Experimental)
How to Install
1. Install the latest vvvv_50beta38.1 (older versions are not supported)
2. In vvvv, middleclick > Show VL
3. In VL, go to: Dependencies > Manage Nugets > Commandline and type:
Versions
- This latest version works best with beta38.1.
- Using beta38 or older? make sure to install an older skia version. Type 'nuget install VL.Skia -version 0.93.26-g6c67991fa4' to get a compatible version. You'll miss some of the advertised features though.
Hello @all,
as you might have read in the VL: ThreeDee blog post, we see two major workflows with vl/xenko. To get familiar with xenko we jumped on a project where the second mentioned workflow, "Xenko game as a host for VL" makes sense.
First contact was better than expected and we were quickly able to patch with the original xenko entities. The nodes we created so far allow to setup the scene graph and also combine it with scenes or prefabs made in xenko's game studio.
We also tested custom 3d drawing á la vvvv dx11 and the performance is crazy good so far! We implemented some pretty complex shader pipelines like a 3d fluid simulation and particle systems and we see insane frame rates, even on laptops.
Scene Graph Nodes
The scene graph is a high level system that has concepts like light, shadow, materials, physics, audio etc. Patching with the scene graph feels quite easy since there is no need to work with shaders directly. Let's see how this looks like:
The entry point into the rendering is the RootScene:

Much like a vvvv Renderer you connect the content to its input. Each object in the scene is a so called Entity. Or in other words, entities are the building blocks of the scene graph. They can be as simple as a Quad or as complex as a complete level of a game. For example the Box or the AxisAndGrid node are entities. Entities can also have children, so we modeled the almighty Group node as an entity with two or more inputs for child entities:

For a basic setup we can connect an AxisAndGrid and a DirectionalLight to the Group:

It might feel odd to vvvveterans to connect AxisAndGrid and DirectionalLight to the same Group. But this is what the engine manages for you, it picks up all entities in the scene graph and builds the correct shaders, render calls, physics setup and so on from it. That is how most modern game engines work, the concept is called entity/component/system (short ECS) and xenko has a nice documentation about it here if you want to know more.
Of course you can still work with custom shaders when needed. More on that in an upcoming blog post.
Now let's finish our little scene by adding a floor plane and a box:
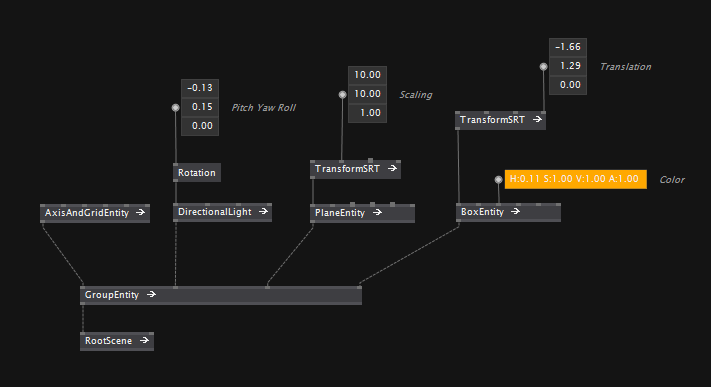
There you have it, doesn't it look nice?

Next Demo
If you want to see more vl/xenko in action, join us at the next vvvv meetup where we will give a bit more insight into the current state of the library: vvvv meetup #5
See you there,
devvvvs
Found another one everyone should know about. The open source GPU debugger RenderDoc works just fine with vvvv and dx11. This can help to profile and debug shaders and your graphics performance and find bottlenecks. I might even prefer this one over the Nvidia one found in the last post. Its open source, the controls feel a bit more intuitive and it should also work with ATI cards:
The steps are pretty simple:
- Download and install: https://renderdoc.org
- Start the application and enter the vvvv instance you want to start:
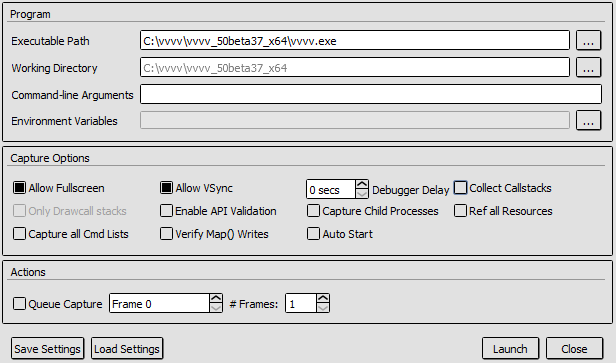
- Press "Launch" and load any patch/scene with dx11 and you should see some debug HUD in the renderer
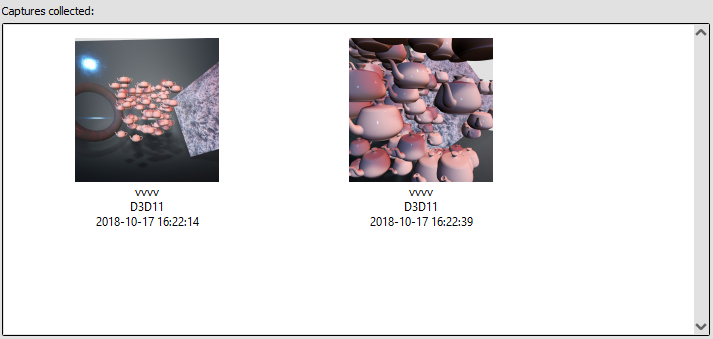
- Press F12 or PRINT to capture the latest frame. Go back to RenderDoc and you should see a list of captured frames:
- Double click or "Open..." a capture to inspect your frame like this:
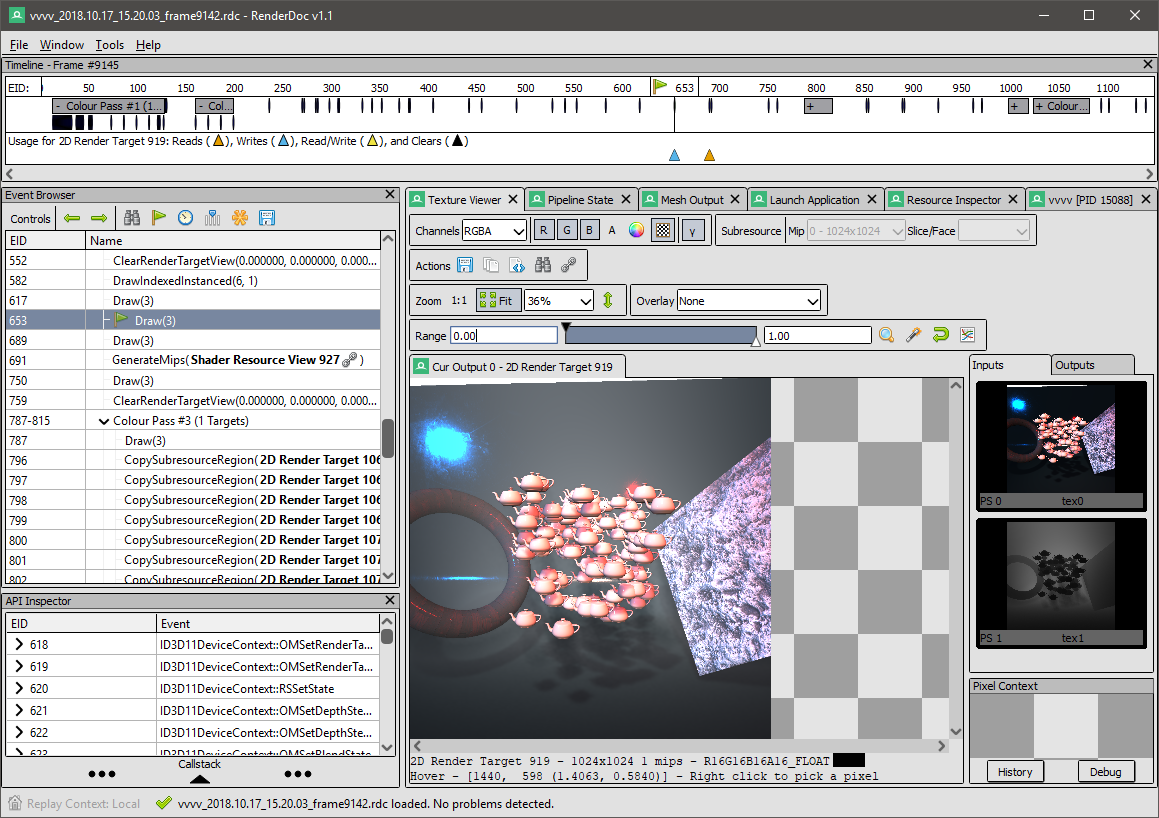
- You can even right-click a pixel and ask for it's history. E.g. which shaders did write into it and inspect the shader and shader resources:
RenderDoc was originally developed by Crytek for the Cryengine and was open sourced in 2014: https://www.cryengine.com/renderdoc
That's it, now you know more.
Yours, devvvvs
Just a quick one found today and everyone should know about. Nvidia Nsight Graphics works just fine with vvvv and dx11. This can help to profile your graphics performance and find bottlenecks.
The steps are pretty simple:
- Download and install: https://developer.nvidia.com/nsight-graphics
- Start the application, click "Quick Launch" and you should see this screen:
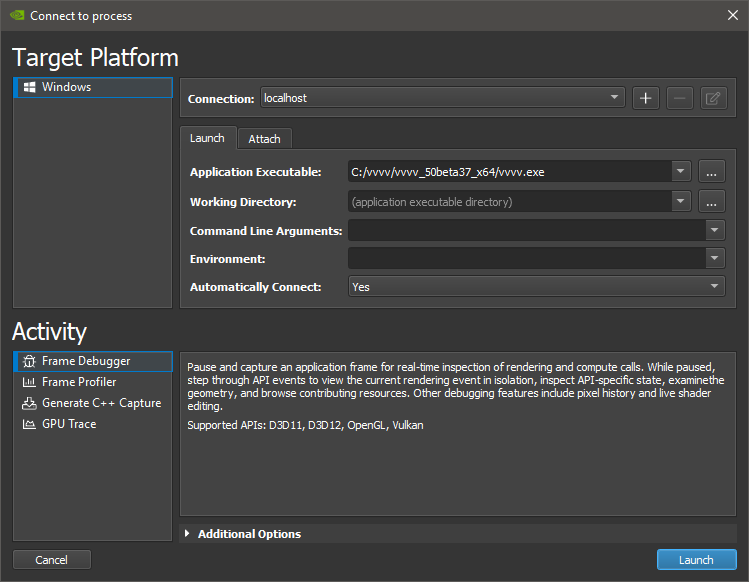
- Add your vvvv.exe and press "Launch"
- Load any patch/scene with dx11 and you should see some Nvidia HUD in the renderer
- Press CTRL+Z and then SPACE to capture the latest frame and bring up Nsight
- Now you can inspect your frame like this:

- Or have more details, timeline, API calls, timings etc. in the Nsight application:
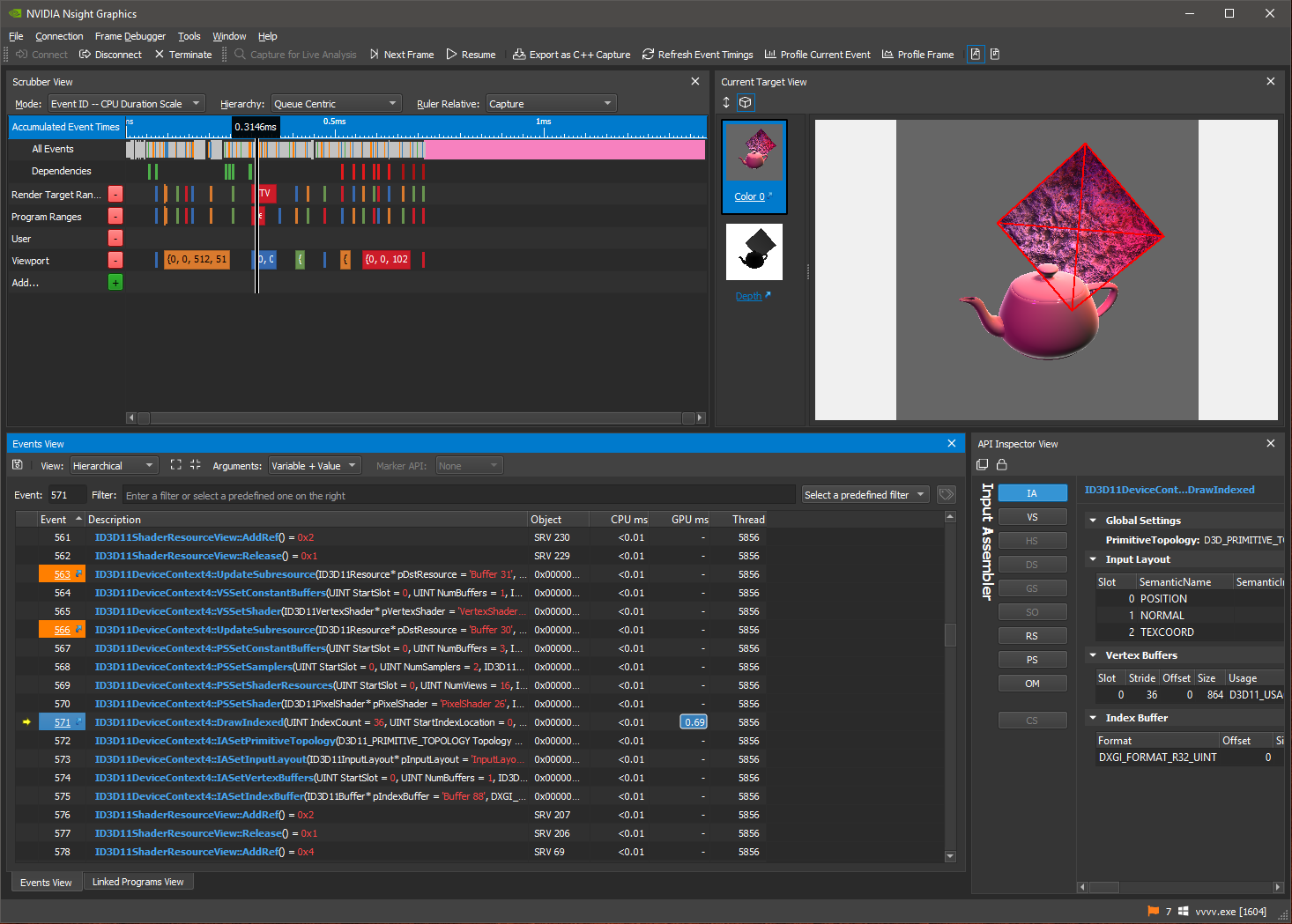
That's it, just so you know.
Yours, devvvvs

hi there,
beta37 is done - as far as we know. Now, please help us to find out!
Try the release candidate - link at the bottom - by opening the project you're currently working on and see if it opens timely, patching is responsive and everything works correctly. If not, please let us know in the forum using the alpha tag.
Release Highlights
Cleanup and cleanup tools
This one can be understood as a late spring cleaning.
To get the desired appearance in the node browser we at times needed to resort, rename and polish nodes and types without changing much in terms of functionality. There were other examples though where we refined some major bits in the basic node set - e.g. file IO and serialization nodes got a complete rework and just got so much easier to use. And we made sure that the core library feels more explorable just by making basic nodes more visible than others. Advanced, experimental or obsolete nodes now don't hide in different packages but can be opted into the list of nodes, while browsing the library. Within that process, we also polished the node browser quite a bit.
But this release also comes with features for you to clean up. Frames help to structure patches in a visual way, groups, and categories in a structural way. You even can tweak the visibility of your nodes in the node browser and by that distinguish rather advanced or still experimental nodes from the daily node set. Library developers will also love the feature to make certain helper nodes internal so that they are free to change or delete them at any time in the future.
A lighter VL
Startup speed got improved. Also, there are less VL documents open making the navigation menu more meaningful. Let me not begin with the much lighter ".Net Packages" menu or the much lighter download size. Process nodes now opt for mutation which makes them lighter in terms of memory allocation.
Entry points and document management
Together these features allow this workflow:
- Drop VL documents onto vvvv or VL to open them. They start running.
- To make them go away use the "close document feature Ctrl-F4" in the VL document menu.
In essence, this allows to do example patches, tutorials or help patches - an essential feature that will make future libraries so much easier to learn. To have a patch start on document load, create a non-generic process called "Root" in the document patch. So again from the end user perspective: no need to create a node in vvvv to see the patch running.
Ctrl-W now behaves like in an internet browser: It just closes the tab - closing the last tab closes the VL window. Ctrl-W doesn't ask you to save the document though. Closing a tab doesn't close the document, it just closes the view onto the specific patch within the document.
If you now managed to hide the VL window use the "Show VL" command in the vvvv main menu to get back into VL.
Debugging
Debugging should feel much more intuitive, as it now allows to inspect the exact state of the patches for the moment when something went wrong.
Some notes on the debugging settings:
- RuntimePauseOnError: When turned on, allows to inspect nodes and pins above the pink node. You see the values for when the exception occurred. For end users, this feature typically is off. Library developers will likely switch this often depending on whether they're debugging or using their library. Reloading the settings now always should work. No need to restart when switching the setting.
- RuntimeAutoJumpToError: if the auto panning gets in the way this is the setting to turn off.
You can switch the settings via Quad menu -> Settings -> Open in editor.
Cache region
Actually we never really told you about how amazing the Cache region is. If you have any node that you want to perform better, ask yourself if it wouldn't be enough to only compute it when the input changes and then cache the computed results. The cache region allows expressing this easily. The cache region actually got added with beta36, but now the interplay with other constructs works better.
Loops for example now output their spreads in a way that the changed-detection of a downstream connected Changed node or Cache region only triggers if the slices actually changed from frame to frame.
Some of this stuff may for sure sound pretty special interest, but we have the feeling that these details matter in the end for having an expressive but playful language.
Baby, don’t make me spell it out for you
All in all this release makes VL easier to learn, use and develop for.
VVVV |
VLVL: Corelib Cleanup |
for an in-depth list of changes have a look at the changelog.
Download
|
Release Candidate 6 64-bit vvvv addons 32-bit vvvv addons |
Beware: Make sure you secure your data. Patches saved with an alpha might lead to not being able to open them with the former beta.
|
Not many will remember the times when vvvv's 3d rendering was based on Direct3D 8. Not important really, because at the same time we released vvvv 33beta1 in December 2002, Microsoft released Direct3D 9 with a lot of new features, so we knew what we had to do..
Luckily vvvv's DX9 implementation proved powerful enough to be quite useful for many years. Then it took Microsoft 5 years to release its successor DX10 which was only available on Windows Vista, which nobody wanted. Also graphic-card adoption took quite a while so we didn't really feel an urge to start working on it right away.
A Gift
A year later in 2008 Microsoft released Windows 7 and with it DX11, which altogether looked more promising. But still a lack of adoption of supported hardware and Windows 7 didn't put too much pressure on us to implement it. Instead we thought it would be smarter to improve the plugin-interface for vvvv to make it easier for users to contribute to the library of nodes.
In parallel we had already secretly started work on our next big thing that would become VL, which we first announced at the keynode during NODE13. Since with VL we've mentioned from the beginning that we wanted it to eventually run across platforms, for us, implementing a new renderer based on the windows-only Direct3D api became less and less appealing.
What happened next couldn't have been more fortunate: besides many other major contributions, using the possibilities of vvvv's plugin-interface, power-user vux took it in his own hands to create a set of nodes for rendering with the features of DX11, which he released on vvvv's 10th birthday in December 2012. And the vvvvorld was a better place.
DX11 for vvvv is amazing, but innovation in the world of computer graphics started moving faster and faster. Despite the magic that DX11 brought, users demanded more and more bling, but all we were talking about was how VL would revolutionize visual-programming, which brought us all together in the first place.
Another Gift?
With the cross-platform goal in mind, for years it seemed the only option was going for OpenGL instead of Direct3D as rendering API for VL. But all those years, following OpenGLs development and stories about bad support by Microsoft and Apple never got us excited enough to just go for it. Meanwhile a new player has appeared as a modern cross-platform graphics API, called Vulkan, but since it is still in its early stages and support for MacOS seems not official yet, again we were reluctant to jump on it.
All the years we knew there would be another option: Instead of using Direct3D, OpenGL or Vulkan directly, we could base a rendering library for VL on a game-engine API that would deal with different graphics APIs under the hood and would possibly have all 3 as back-ends that can be used on different platforms without us needing to worry about it.
While this sounds brilliant, it obviously has other potential drawbacks (out of scope for this post). But also the range of options for game-engines we could have used wasn't too overwhelming. Until recently. Enter Xenko.

Xenko is a universe of its own and as such comparable to Unity3D, UnrealEngine, CryEngine and the GodotEngine. Please check Xenko's propaganda page to get a glimpse of its features.
We've had an eye on this engine for a while already but it being targeted at commercial game-studios would mean that every user of vl would also need to buy a license for it, so again we were hesitating and looked for alternatives.
But what just happened could again not have been more fortunate: The company behind Xenko, Silicon Studio, removed its commercial licensing and released it to the community under the MIT license, which is a very permissive open source license. This would allow us to base a renderer for VL on it without any licensing restrictions.
Xenko and VL
Initial tests look very promising. Within just a few days we were able to patch a little interactive scene and export the project as an executable so it could be distributed via the Steam store and run on a VR device.
Hence our plan is to investigate further in this direction and at the moment we see two interesting workflows between VL and Xenko:
- a VL.Xenko pack: that would be basically like the VL.Skia pack we've just released
- Xenko Studio as a host for VL: that would be similar to how vvvv is hosting VL at the moment
For both scenarios what will be important, is a proper library design wrapping the original Xenko functionality into a comfortable set of nodes, similar to what we just did for Skia.
Next Steps
We'd usually not water your mouths before we are more sure about things. But with Xenko just having gone full open-source and looking to build a community of developers and users, we thought it would be a good idea to talk about this now and try to involve you from the beginning.
So if you're curious about Xenko's universe, just head over to its website and see what it has to offer. You can even download and play around with the editor and if you're familiar with C# create a little game with fancy graphics and assets in no time.
Next we'll demo what we've got so far to participants at LINK and start a discussion there. If you're not at LINK please still join the discussion with your thoughts using this thread. If all goes well we should also be able to share our proof of concept sometime after LINK.
So we hope you understand that at this stage it is too early to promise anything but at the moment we are confident to having found the right library for implementing a 3d rendering system for VL. Just as we were happy when we finally found Skia as the perfect library for VLs 2d rendering system.
Meanwhile please help spread the word about Xenko, retweet their announcement and consider supporting their Patreon to help them build a strong developer community.
We'll update you about developments as we progress...
VL: Xenko 3D Engine Update #1
VL: Xenko 3D Engine Update #2
VL: Xenko 3D Engine Update #3
anonymous user login

Shoutbox
~2d ago
~8d ago
~8d ago
~9d ago
~22d ago
~1mth ago
~1mth ago
~1mth ago
~1mth ago
~1mth ago