Blog
Blog-posts are sorted by the tags you see below. You can filter the listing by checking/unchecking individual tags. Doubleclick or Shift-click a tag to see only its entries. For more informations see: About the Blog.


My dear vvvv users,
we've scheduled beta 35.7 for release at the end of the week. To make it as polished as possible here comes a release candidate for you to tamper with. Download it, try it and report any findings in our forums.
Also note that this release will be the last one before NODE17. So workshop hosts especially should have a look at it whether or not everything they need is in there and working.
The noteworthy changes are
VVVV
- All Editors from the editing framework have a Gizmo manipulator.
- Links will be drawn red when the pins don't match anymore. Invalid links are stored in patches so that they can be reestablished when they match again. This should be helpful for dynamic plugin and VL development.
- More love for enums: enum spread shuffling nodes finally behave as wanted, GetSlice added, simplified internal encoding. s/r nodes performance restored
VL
- You can search inside patches (Ctrl+F) or across all the currently opened VL documents (Ctrl+Shift+F)
- The whole document structure can be browsed with the new solution explorer (Ctrl+J)
- The default patch type "Patch" is now called "Process" and all patches types in the category VVVV are now picked up as nodes inside vvvv (previously only "Class" used to work)
- Unified user interaction - double click always opens node browser, right click always opens context menu
- Links will now snap to pins
For an in depth list of changes have a look at the changelog.
Download
64-bit
vvvv (35.7_rc5)
addons (35.7_rc5)
32-bit
vvvv (35.7_rc5)
addons (35.7_rc5)
This release is intended to be the last one of the beta 35 series. We changed plans a bit and deliberately kept the rather big internal feature branch (which allows you to drag'n drop .NET assemblies onto the patch) out of this release as it will need a longer testing period in the alpha build channels.
Dear pointmovers,
from now on you can translate, rotate and scale way more faster.
There is a Gizmo for that.
And every Editor in our EditingFramework has it inside.
- Press 'g' to turn a Gizmo On/Off
- Pick and drag its handles to transform the points
- Hold 'Shift' for uniform scaling
- Nudge points with arrow keys
The Gizmo is working in both DX9 and DX11 worlds.
See Editor's helppatches.
Nothing more to say.
Easy.
Available in the latest Alphas.
As you may have noticed, we are back in our every 2 month release cycle and a new beta is up on the horizon.
As we have noticed, not many of you use alpha builds to test it against your latest an greatest projects. So here is a particular fine alpha version that is our release candidate for beta35.5 scheduled for Monday.
Please give it a test run with a few patches and send us reports on any bug or problem you encounter. Testing is also the perfect excuse to miss any Easter obligation.
New VL nodes
Also try out some new goodies that you can find here:
XML and JSON
Event based MIDI
Reactive Programming
And even more: Change Log
Temp file issue
Some have reported that they are seeing ~temp files being written on save. We could not reproduce the error here, but we have now an error pop-up to inform you when something goes wrong and the exception that caused the problem will be copied into the clipboard. Open the projects that have that issue and paste the exception message into a new forum thread to help us tracking it down.
Download
64-bit
vvvv_alpha35.5_x64_rc4
addons_alpha35.5_x64_rc4
32-bit
vvvv_alpha35.5_x86_rc4
addons_alpha35.5_x86_rc4

Here is something really great. The new Reactive category gives you tools to handle asynchronous events, background calculations and even enables you to build your own mainloop that runs on a different CPU core. But let's start with a pragmatic explanation of what it is:
Reactive programming is programming with asynchronous data streams
In a way, this isn't anything new. Event buses or your typical click events are really an asynchronous event stream on which you can observe and do some side effects. Reactive is that idea on steroids. You are able to create data streams of anything, not just from click and hover events. Streams are cheap and ubiquitous, anything can be a stream: variables, user inputs, properties, caches, data structures, etc. For example, imagine your Twitter feed would be a data stream in the same fashion that click events are. You can listen to that stream and react accordingly.
On top of that, you are given an amazing toolbox of functions to combine, create and filter any of those streams.
Since a while VVVV and VL use these so called Observables to handle external events (i.e. mouse, keyboard etc.) and asynchronous data. This was mostly under the hood and the actual operations for observables are hidden in the VL.DevLib. The reason is that out of the box the operations do not go well together with the frame based Update concept of VL because they are intended to be called only once or when something has changed. But as of now we have wrapper nodes for the most common observable operations that do exactly that, listen for change and only rebuild the observables when necessary.
Processing events
The go to node for handling events is definitely ForEach Region (was Region (Stateful) in earlier versions) in the category Reactive. This region allows you to place any node inside and can also remember any data between two events. There is also one with version Keep that can filter out events using a boolean output. This region is very similar to the ForEach region for spreads, only that its input and output is event values in time instead of slices of a spread.

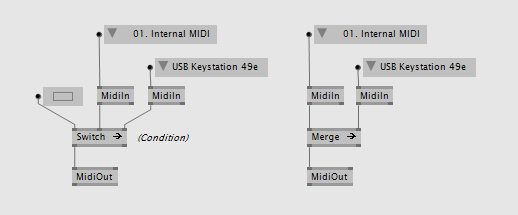
You can switch or merge event sources:
There are also filtering options with OfType or Where:
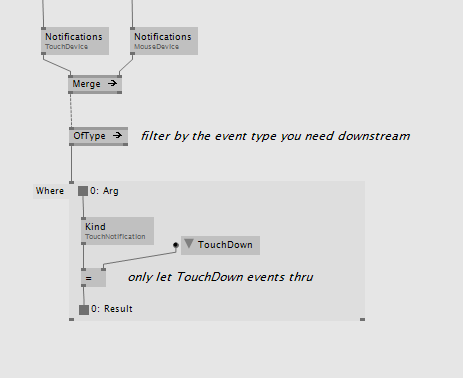
Other nodes include Skip, Delay, Delay (Selector), Scan, Switch, ...
Receiving events
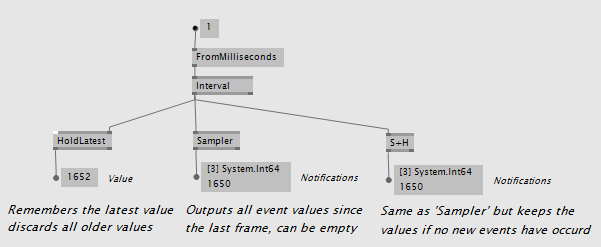
If you want to leave the observable world and pass event values to the mainloop use one of the 3 nodes HoldLatest, Sampler or S+H which all behave a little bit different. Depends on what you need:
Creating events
It's also pretty easy to generate event sources of your own:
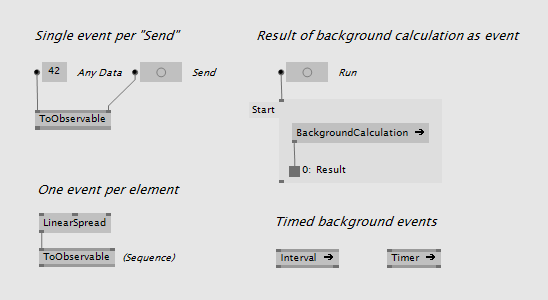
As a general advice, only send values of type Record as event data because they are thread safe. If you send values of any Class type be sure that you know exactly what you are doing.
Observable<Observable<T>>
Yep, totally possible and has useful applications. But i am just gonna let this idea sink in for now...
Further reading
The above just scratches the surface of whats possible with the reactive framework. If you want to know more browse some of the following links:
The pragmatic Rx expert from the quote above:
2 minute introduction to Rx
Visual explanation of the observable operations:
Operator Reference with marble diagrams
Videos from the creator team. Note that IEnumerable is called Sequence in VL and Spread is also a Sequence:
Erik Meijer: Rx in 15 Minutes
Erik Meijer and Wes Dyer - Reactive Framework (Rx) Under the Hood 1
Erik Meijer and Wes Dyer - Reactive Framework (Rx) Under the Hood 2
For coders:
Introduction to Rx

Midi was released in 1982 and is one of the most successful hardware communication protocols in the world. The simple nature of the protocol makes it easy to implement and even more important, easy to understand for humans.
This makes it a perfect example for the first event based library in VL using the MIDI-Toolkit developed by Leslie Sanford.
Modularity
Instead of having all settings on one node, functionality is now separate to allow arbitrary combinations.
Devices
Device nodes have an enum input for the input/output device driver you want to use. You can have many of them, even for the same driver. Under the hood they will share the actual device driver resource. The driver is opened only if it is necessary, for example if there is an event sink listening to it.
The dynamic device enum will update as soon as a midi device is connected or disconnected to the machine. So no restart required on configuration change:

MidiIn has one observable output for all midi messages received on the given device. MidiOut has one input that accepts an observable to send midi messages to the given device.

Message Filtering
Following the midi message structure, there are filters that allow you to select only the messages you are interested in. For example only midi clock messages, or messages on a specific midi channel:

Message Handling
For all midi message types there are specific nodes to read the message content or construct new messages. These are mostly the native methods of the MidiToolkit library.

Event Based Processing
You can process a midi message (in fact any event) directly as it occurs. The new ForEach region in the Reactive category executes it's patch for each event that is passed in and can transform the event into a different message type and decide whether to pass the current event on via the Keep output.

This is part of a bigger programming paradigm that was also polished for the new midi nodes. Definitely check out for the blog post on Reactive Programming.
Events vs. Mainloop
To Mainloop
At some point all async input event handling in the background will be over and you want to leave the observable world and have the processed values in the main loop. For that there are several options:
For supereasy controller value input there is ControllerState or NoteState:

For more advanced scenarios refer to the Reactive nodes HoldLatest, S+H or Sampler which provide ways to pass event values safely to the mainloop.
From Mainloop
If you want to generate midi messages in the mainloop you also have a simple node that generates controller message events:
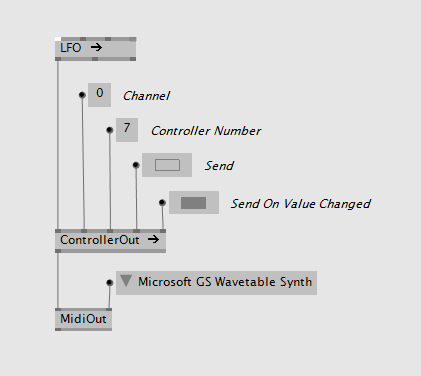
For other messages use the Reactive nodes ToObservable which create an event source that you can use to send events from the mainloop.
Spreading
Since VL makes a difference between a single value and a spread of values, some nodes come in 'plural' version to allow listening for example for multiple channels at one.

ahoi,
one of the more basic things any programming library has to support is parsing and the creation of XML data-structures. since vl is based on .net we don't have to invent anything here but can make direct use of .nets XDocuments, XElements, XAttributes datatypes. so we're happy to announce that in cooperation with dominikKoller we added xml/json support for vl:
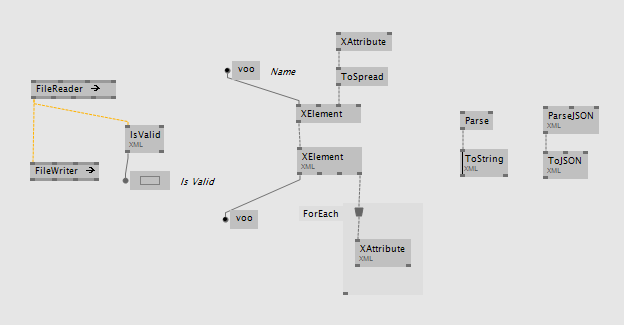
- read/write (async) XDocuments from/to disk
- parse an xml-string to XDocument
- convert an XDocument to an xml-string
- join/split XDocuments, XElements and XAttributes
- use XPath, XSLT
- check for validity against a given schema
plus:
- read (async) JSON files from and get and get them as handy XDocuments
- write (async) XDocuments to disk in form of a JSON string
- parse a json-strings to XDocument
- convert an XDocument to a json-string
so basically anything you could already do in vvvv plus some more. and this is only what we brought to the surface for you. using the underlying .net datatypes (XDocuments, ...) directly, a pro-user will (later) easily be able to use the whole range of functions that those datatypes provide for more advanced use-cases.
so, once again, something for the whole family..available in latest alphas now.
gut patch!

Pointmovers of vvvv!
The Editors got some new features.
Stepping through the points via Keyboard
- Q - next point
- Shift+Q - previous one
- Space - select point
- W - switch between Controls of a Knot (in a Bezier Editor).
Marquee selection in a Bezier Editor
- If Points are getting selected, Controls are ignored.
- Press F - to Force selection, it allows to mix the selection of Points and Controls.
Support for DX11
The Editors by itself are graphics-engine-independent, but their points, lines and handles must be rendered. From now on there are DX11 Views for every Editor.
The Editors:
| 2d | 3d |
Available in latest Alpha builds.
See also:
previously on devvvvlopment: vl-networking-and-async
With beta35 (including VL) out in the wild and people apparently starting to use it (see forum threads about it) we're quite happy with the feedback so far. We know of people already including VL in their daily patching and getting the hang of it. Others are still more cautious and are waiting for better documentation or are hoping for node17 to open their eyes. All fair enough, no pressure.. in any case the question is of course:
What next?
One of the many aspects that vl will be different when compared to vvvv is its node-library. In vvvv we have a closed-source base-library (written in delphi and closely bound to the vvvv core) plus a wide range of open-source nodes including community contributions (written in c# via a plugin-interface). For vl we'll still distinguish between a base-library and the rest, but all libraries will work the same way, ie not be bound to the core. And not even need a plugininterface. And be open-source.
So from the beginning in vl we separated core from libraries and already have a git-repository including all of VLs libraries organized in neat packages (as you can basically already see in your beta35\lib\packs) that we're ready to open. Why haven't we done so already? Well, by releasing library source-code we're kind of committing to a style that everyone should be able to use to write nodes for vl. Therefore this is really a crucial part that we simply wanted to give a second look.
Remember when at node15 we teased how to define nodes for vl? Everything already felt fairly simple indeed. The typeimporter, a breeze. As mentioned in previous blog-posts we've been continuously importing libraries ourselves since then and noted a few things that we needed to improve to make the workflow for future library developers even more convenient.
So this is what we're reworking at the moment and what we hope to be releasing soon:
- the complete vl node library as open-source
- documentation on how to import/write your own nodes/libraries for vl
- documentation on how to package your libraries for consistent distribution
This will reduce the barrier for developers enormously because everything they have to do to contribute to the vl nodelibrary, will be very little vl-specific and very close to what any c#/.net developer is doing anyway.
Other than that our focus until node17 will continue to be the integration of vl with vvvv, improving documentation and adding the one or other smaller feature. So, that at node17 we have a strong foundation to teach on and hopefully even already some new, contributed libraries..
Until the next update,
good patch!
previously on VL: vl-progress-report-4
things you know
the vivid blog reader already knows the drill: everything stays the same if you liked it just the way it was.

Specify remote host (IP address), a nice port number, connect some data and bang the send to let your UDP packets travel over the network. Or open a server to receive bytes arriving on the specified port. The only difference to vvvv you might see is, that here you also get infos about the sender of the packets via the Remote Endpoint output (which is an IP Address and a port)

same same for the TCP nodes: The client will try to connect to a server. And once the connection is established, you can send and receive bytes.
The TCP Server awaits incoming connections to talk to. The subtle difference here is the Tuple input, where you would expect the data pin. No one ever requested it, but now you can decide which packet should be sent to which client by specifying IP address and port together with the message. In case you still want to send the same packet to all of your clients, just set the address to 0.0.0.0 and port 0
UDP & TCP revisited
so why did it take so long, what's the goodies behind that?
Unlike the monolithic networking nodes in vvvv you can peek inside the VL ones. The goal was modularizing on a much lower level to be able to provide the very basics as nodes for the patcher:
- Timeout on send and receive (you have that one via @phlegma in the TCP (Network Client Advanced) node in the addonpack)
- access to Local Address and Local Port: means you can have senders and receivers bound to different networkcards (not just listening to any packet coming in on a certain port as it was now, or relying on the system automatically chosing the right card to send from)
- amongst which cards are available and running, get all sorts of information about the network capabilities of the system
- The guts of UDP and TCP are tightly built around Berekley Socket where you have tons of infos and code snippets on the web. untested yet, but you should be able to tinker your own networking magic, e.g. speak the raw IP protocol directly.


Good news everyone, from now on you're getting a brand new node able to talk to your loaded-with-firmata Microcontroller Boards (like Arduino, Teensy, Particle.io, ...):
- FirmataBoard (Devices)
Together with jens.a.e (author of the original Arduino (Devices StandardFirmata 2.x) ) we've looked for a more convenient, easier and faster way to patch microcontroller related ahhmm... patches.

With this implementation:
- Just plug a DigitalWrite (Firmata), AnalogWrite (Firmata) or ServoWrite (Firmata) node to the FirmataBoard node (or concatenate them together) to set the pins of the Board.
- Connect DigitalRead (Firmata) and AnalogRead (Firmata) nodes to get the values from the Board's pins.
- Use the Sysex Messages output to receive different 'Sysex Messages' sent back by the Microcontroller Board. Some Sysex decoders are already there (see StringDecoder (Firmata), CapabilityResponse (Firmata), FirmwareResponse (Firmata)). Sending custom 'Sysex Messages' is easy as well.
- The node is able to talk to any microcontroller board loaded with the standardized Firmata firmware without any further configuration. In the Arduino-world such Firmata firmware is called "StandardFirmata".
- Have some custom Firmata running on your chip? Just provide the configuration manually using the BoardConfig (Firmata).
Easier than ever before:
- no need to supply a spread for all 20 pins and then SetSlice some of them to particular values.
- no need to define the 'PinMode' for each pin.
- no need to define which pins should report their values back.
Thanks:
Hardware for the development was kindly provided by QUADRATURE.
p.s.
Oh, by the way, these new Firmata nodes are fully implemented in VL.
p.p.s.
And of course there are some caveats.
- The Cons (Firmata) has only 5 input pins which are interleaved with 'BinSize' pins. But note that you can cons multiple cons nodes... (for now)
- The VL nodes eat more processor ticks as their C# counterparts. Working on it...
The nodes are now available in Alpha Builds.
This is a rework of the original release of 'Arduino Second Service'.
See the previous (now outdated) blogpost.
anonymous user login

Shoutbox
~1d ago
~1d ago
~5d ago
~13d ago
~21d ago
~1mth ago
~1mth ago
~1mth ago