Blog
Blog-posts are sorted by the tags you see below. You can filter the listing by checking/unchecking individual tags. Doubleclick or Shift-click a tag to see only its entries. For more informations see: About the Blog.

With the release of vvvv gamma 2019.2 we introduced a new backend compiling patches in real time using Roslyn. This blog post is primarily intended for a technical audience, if you're solely interested what new features it brings to the table have a look at the before mentioned blog post.
Background
In the past VL (the language behind vvvv gamma) compiled in-memory directly to CIL using CCI. With the recent changes in the .NET ecosystem and CCI being superseded by Roslyn it became more and more apparent that at some point we'd also have to make the switch to keep up with the latest developments happening at Microsoft.
What finally pushed us into making the switch was two-folded:
- An executable written by CCI wouldn't work at all the moment it referenced a library based on .NET standard. This was a major set back as nearly all future libraries would be targeting .NET standard and days of trying to find a workaround brought us nowhere. Making modifications to the already abandoned project CCI seemed like a very bad idea.
- For a long time, we didn't know how to directly translate VL's adaptive nodes feature to CIL (or C# for that matter). For those who're not familiar with adaptive nodes, it allows one to build functions solely on their intent. For example, a LERP function can be expressed with a PLUS a MINUS a ONE and a SCALE node without having to specify what data will be provided in the end. The exact implementations will be looked up by the compiler when applying the function let's say on a float or a vector. This lookup is done from an entry point (like an executable) and while traversing from such an entry point all adaptive nodes will be replaced with their respective implementation. The emitted CIL code will then end up with two LERP functions, one for float and one for vector. This approach was working fine but it had a major drawback as it prevented us from pre-compiling our libraries and also it prevented any user to build a proper .NET library with VL.
Until this year in march @sebl came to the rescue by randomly dropping us a link in the chat pointing to a neat little "trick" which suddenly made it possible to translate our adaptive nodes feature directly.
After initial tests in March and April and having the patched tooltip feature still pending for the final release, we decided to let myself jump into the rabbit hole which I've finally crawled out of after more than half a year ;)
The neat little "trick"
Let's go back to the example of the LERP node and let's further try to write it down in C#:
T LERP<T>(T a, T b, float s) => a * (1 - s) + b * s;
Looks neat but sadly won't work, C# will tell us that the operators +, - and * and the constant 1 are not available on T.
The trick to make it work is to outsource those operators to a so-called "witness" which in turn will provide the implementation when the LERP gets instantiated with say a vector. So let's see how the actual needed C# code is gonna look like:
with
interface IPlus<T> { T Add(T a, T b); } interface IScale<T> { T Scale(T a, float s); }
and when applying it with say float we need to define a witness implementing the needed interfaces
struct MyWitness : IPlus<float>, IScale<float> { public float Add(float a, float b) => a + b; public float Scale(float a, float s) => a * s; }
which finally allows us to call
LERP<MyWitness, float>(5f, 10f, 0.5f)
Fancy, no? The beauty is that when the JIT compiler hits such a code path it will be smart enough to inline all calls so in the end for the CPU the code to execute is the same as the initial naive attempt. But don't worry, this is all happening behind the scenes. In the patching world, it is as simple as it was before to patch generic numeric algorithms.
The implications
So now that we're able to translate patches directly to C# what are the implications apart from being able to export an application?
Easier to maintain
Well for us as developers it will be much easier to bring in new language features, because the code we generate will be be checked by the C# compiler and more important, we can fully debug the generated code with Visual Studio. That by the way is not only restricted to us, anyone can now attach a debugger to vvvv (or the exported app) and debug the patches.
Faster loading times
The generated C# code will make full use of .NET generics. So when building a generic patch the generated class will also be generic in the pure .NET world. As an example let's consider the Changed node, while in the CCI based backend a Changed class was emitted for each instantiation (Changed_Float, Changed_Vector, etc.), the new Roslyn based backend will only emit one Changed<T> class and it is left to the JIT compiler of .NET to create the different versions of the needed target code. This should lead to much less code the CPU needs to execute as the JIT compiler is much smarter on when to generate new code and when not.
But what's even more important is the fact that it opens up the world of compiling VL patches as pure .NET libraries. So we can finally pre-compile our libraries (like VL.CoreLib, VL.Skia, etc.) which in turn reduces the general overhead and leads to much quicker loading times and less memory usage. As an example loading the Elementa "All At Once" help patch takes ~15 seconds the first time (compared to ~33 seconds in the old backend) and thanks to caching to disk only ~8 seconds when opening at a later time.
Instantiate patches at runtime
Apart from better loading times, it also gives the patcher the ability to instantiate any VL patch during runtime. In the previous backend, one had to use a hack and put all possible instantiations into a non-executing if-region. This is not necessary anymore as all the patches get compiled. However, I should mention here that this is only true for non-generic patches. Generic patches usually require a witness which is not so straight forward to provide.
The drawbacks
Sadly the new backend also required some major internal changes in the frontend so it wasn't possible to guarantee existing patches would work the same way as they did before. Here follows a list of potential breaking changes:
- The type unification algorithm had some flaws and therefore needed modifications. In general, it is "smarter" than before, so when starting a patch from scratch fewer annotations should be necessary. But for existing patches, it sometimes finds a different solution than the previous algorithm leading to red links on the application side of a patch. In those cases, one needs to set a type annotation in the patch definition.
- When pause on error is enabled the old backend was able to show computed values up to the point where a node was crashing, this feature is sadly not available anymore due to local variable scoping rules of C#. Whether we'll bring this feature back or not is not yet decided.
- Naming rules are more strict, so it's not allowed anymore to have for example an "Update" and and "Update (Internal)" operation as both are considered to have the same name. In general instance-operation overloading is not possible.
- Static operation overloading - having operations with the same name but different pins - is still allowed as long as the types of the pins differ. So different pin names alone are not ok.
- When defining a generic interface all type parameters of its operations get assigned to the interface itself. This is necessary due to how internals of the emitted C# code work.
- The cyclic graph detection wasn't correct. This can also lead to red links now but should be considered a good breaking change as it makes the patcher aware of undefined execution order.
- Patches, where the execution order wasn't defined, might behave differently now.
привет,
as mentioned previously, elias and me were at DotNextConf in early November where we talked vvvv to a whole different audience than you are. We titled our presentation "vvvv - Visualprogramming for .NET" hoping to get the benefits of what you all take for granted (that is "live, visual programming") across to people who are still stuck with an EDIT/COMPILE/RUN mode of development. And to hear if they could see some application of it in their fields.
The general feedback can be summed up as "Huh, this looks interesting, but I don't know what to do with it". Clearly our demonstrated use-cases didn't resonate with them. A few people came up to us after the talk and were interested in details about the state hot-reload and one guy told us he is working in aero-space engineering and he believes they could very well use it: When working together with physicists they often need to exchange code with them but they always deliver very bad code, he claimed. He saw vvvv as a perfect fit of a tool they could prepare some high-level nodes in, so that the physicists have a tool to experiment with, where they cannot make too many mistakes... Interesting take and in a sense exactly what we were hoping for. So let's see where this goes...

Now grab a drink and some snacks, this goes for 50 minutes:Watch on Youtube
Just in time!
Only a whopping 6 years and one and an half months after its first mention during Keynode 13 and to the day exactly 5 years after the release of the The Humble Quad Bundle, you can finally hold it in your own hands. Not exactly as the full release we had planned but as a preview:

To our own surpise we couldn't finish all the things we had planned to release today. Most notably the "windows executable export" didn't make it. We know this is a bummer, but we want to get this right and it just needs some more time.
Apart from that we figured there is no more need at this point, to keep it to ourselves. It is definitely good enough for a preview, definitely good enough to gather some feedback to incorporate into the final 1.0 release for which we take some more time to finish our plans. So let's have a look at what we got:
What's new compared to the vvvv beta series
LanguageBesides staying true to its nature of being a an easy to use and quick prototyping environment, vvvv is also a proper programming language with modern features, combining concepts of dataflow and object oriented programming:
|
Node LibraryWhile for now the number of libraries we ship is limited, the fact that you can essentially use any .NET libary directly mitigates this problem at least a bit. Besides there is already quite some user contributions available in the wip forum and here is what we ship:
|
Forum
To accommodate for the fact that from now on we essentially have 2 products, we added two main categories to the forum:
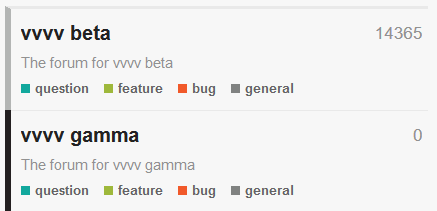
The existing question, feature, bug, general sections were moved into vvvv beta, and the vvvv gamma section got its own question, feature, bug and general sub-sections. Note that by default the search is constrained to the category you're currently viewing. When you're using vl in beta, still feel free to ask questions in the beta forum. We'll handle that.
Tutorials
Head over to this forum section to watch some video tutorials:https://discourse.vvvv.org/c/tutorials
Pricing
We've previously announced the upcoming pricing model for vvvv gamma, which we're currently refining and we'll update you on changes to it soon.
Until further notice, the previews of vvvv gamma are free of charge but due to its preview-nature we don't recommend using it in commercial scenarios yet.
Download
Here you go: vvvv gamma 2019.1 preview 975
Changelog:
975 26 11 19
- works with VL.Audio
- Fixed race condition between state disposal and OnNext calls in reactive ForEach regions. Was responsible for an access violation in OpenCV tooltips.
959 19 11 19
- equals version included with beta39
- can now create a node while linking by simply starting to type (double-click not required anymore)
- fixed SVGWriter
- fixes on bumpy Damper
- removed a few unnecessary Damper versions
- fixed time step calculation of Damper (Fast)
- Dampers can now be used in loops
- fixed image tooltip
- fix on tooltip layout
- some color operation improvements
930 02 11 19
- fixed annoyance with nodes being selected instead of dragged
- fixed problem with red nodes not updating after installing VL. nugets
- fixed time step calculation of Damper (Fast)
923: 31 10 19
- added ToVector2/3/4 (Float32)
- fixed Tokenizer (Frame)
- fixed register services method called too early
- fixed regression that timings wouldn't show up on regions
- fixed timings not working on Cache region
- fixed serializer not dealing with fields of type object correctly
- fixed serializer crashing with a stack overflow when data like vectors or colors stored in an object field were re-interpreted as arrays
- fixed IL emitter not picking up type dependencies on fields if the type was a generic type instance (https://discourse.vvvv.org/t/weird-reference-documents-behavior/17949)
- added Random implementation for RGBA
- fixed hue calculation and minor improvements in color space conversions
- added String <-> Array<Char> conversions
- shutdown dialog now lists unsaved documents
- installer adds windows defender exceptions
827: 09 10 19
- setup.exe is now signed and shouldn't trigger "windows protected your PC popup anymore"
- added Quad>Windows>Key/MouseDisplay
- fixed GrayScale Skia ColorFilter
- added Damper/Oscillator 2D, 3D
- Packages are now in AppData\Local\vvvv\nugets
703: 16 09 19
- tooltip performance improved
- ImageReader now returns correct format of images
- added FromBytes (SKImage)
- added Resize (SKImage)
- LinearSpread now has Phase input
- added midi ProgramChange node
667: 03 09 19
- added IsEven/IsOdd nodes
- added Morph node
- added MultiFlipFlop node
- added ConnectAll node
- added CounterFlop
- added Random (Centered)
- added Sort (FormerIndex)
- added OrderBy (FormerIndex)
- added IndexOf (KeySelector)
- added Search
- added Search (KeySelector)
- added Resample nodes (Point, Linear, Repeat, Hermite, BSpline)
- Switch node can now have more than 2 inputs
- Filter node now has TweenerMode exposed
- Nodebrowser now also looks for tags in nugets
- FromImage (Skia) now has options for the case of R16->R8
- FromImage (Skia) now handles 24->32bit conversions
- ADSRSettings has optional inputs for Attack, Decay and Release curve settings
- ADSR has an input to set a new clock at any moment
- fixed AddRange (Array) of SpreadBuilder
- updated VL.OpenCV to 0.2.129-alpha
618: 22 08 19
- SVG/PDFWriter now deal with background correctly
- improved some warnings
- increased max tooltip height
615: 21 08 19
- more tweaks for tooltips
- Ctrl+F now also considers nodes category
- updated to VL.OpenCV 0.2.122
573: 08 08 19
- pin tooltips now show their infos again when available
- copying messages from tooltips is now via ctrl+shift+c
- added simpler Mouse and Keyboard (Skia.IO) nodes
- skia primitives (rect, circle,...) now come in two versions, instead of as overloads
- updated to VL.OpenCV 0.2.121
552: 01 08 19
- reworked tooltips
- new settings: MouseMiddleButtonOpens to activate middleclick to open patches of nodes
- addded node: FromImage (MutableArray)
- added skia ColorFilter nodes: Transform, Brightness, Contrast, Grayscale, LUT
411: 12 06 19
- Value to bytes nodes now have defaults
- Fixed somehow newly introduced crash in patches making use of serialization (like Tilda) or reflection API (like the runtime-model-editor demos)
- Fixed accumulators on loops being auto-disposed causing object disposed exceptions in more complex patches (ike Tilda)
- Fixed Sampler (Reactive) getting stuck in an endless loop if upstream observable crashed (also seen in Tilda)
406: 10 06 19
- Fixed crash when creating IOBoxes in regions while linking
- Fixed pin highlights when linking via region border point
- Fixed application restart with F8/F5
- Skia gradient nodes rework
398: 05 06 19
- fixed couple of regressions in compiler introduced between 369 and 380
- fixed splash screen flicker
- fixed a null exception on startup
380: 01 06 19
- fix for Tokenizer (Frame/Postfix) with empty separators
369: 27 05 19
- Skia PerfMeter (F2) now measures full paint time
- fixed "Countdown" output of Trigger node
- fixes in compiler
- performance improvements in compiler
- added pixel format R32G32F to imaging
- fixed a freeze in Tokenizer
- added Tab, CR, LF, CRLF nodes
- added serializer for Range
- theme and interaction improvements
- added Skia checkerboard style that can be used as a paint
- fixed removing .vl doc references
344: 14 05 19
- PerfMeter in Skia renderer (F2) now shows UpdateTime and RenderTime
- added checkerboard style that can be used as a paint for any layer
- improved scrolling behaviour for sliders
- CoreLib improvements
- sped up RepellingCircles demo patch
- several compiler fixes
- compiler performance improvements
318: 09 05 19
- frames now let you choose colors from a palette instead of the color chooser
- frames now move their content along as you drag on their titlebar
- frames now only move elements that are fully contained
- frame is now included in the "surround with" context menu
- press SPACE to force-include frames in selections
- in inspektor changing precision for floateditor now also sets precision for min, max and stepsize.
- can now grab border control points on regions properly without interfering with region resize
- default culture setting is now invariant
303: 08 05 19
- fixed missing dependency for VL.OpenCV
301: 07 05 19
- windows timer is set to 1ms on start
- mainloop uses less performance and doesn't block windows messages
- Skia Renderer has PerfMeter build in, toggle with F2 when selected
- fixed dpi problem with text in SymbolFinder
- ctrl+T/ctrl+shift+T to bake/clear type annotations on datahubs
- fixed "invalid cast in typeunification" error
287: 06 05 19
- shortcuts now work with all tabs closed
- Renamed action "Assign->Pop" to "Assign->Clear assignment" to make it easier to understand what the action does
- Firmata: Tokenizer was stuck in an endless loop
- fixed null exception in ResizeSelectedMouseHandler
- Typewriter: Shift+PageUp/PageDown - select to the beginning/end of the document, cursor stays at the same column.
- OverlayEditor now has minimumsize (again)
- ImageEncoder doesn't have the bmp option anymore as skiasharp can't encode into bmp
273: 02 05 19
- fixed another problem with editors/tooltips and high dpi settings
- fixed "ReguarExpression" typo
- AllAtOnceEditor for vectors now sticks to value of first component
- fixed problem with enum-editors on pins getting stuck
- no more duplicate "Horizontal" entry in IOBox inspektor
- inspektor now also shows elementtype properties for Spread<Vector>
- serialization for custom types doesn't throw errors for inspektor/defaults
- upstream dis/connected iobox no longer looses its settings
- added GroupBy (Length) and GroupBy (Count) nodes to split a spread into spread-of-spreads
- added Clean node: removes slices with empty strings
- added RepellingCircles skia demo
252: 27 04 19
- fixed dpi handling for fonts in editors
- can now set ApartmentState of BusyWaitTimer to make UI threads
- mainloop now has high precision
- added PerfMeter to VL.Skia
- editing comment/string now keeps size of editor
- comments now have correct initial size
- StringEditor on pin now has wider fixed width
- fixed problem with paddings differing between single and multiline textbox
- fixed setting bool pin value via dragging
- fixed interaction in signature view of patch explorer
- fixed deadlock when implementing interfaces
230: 24 04 19
- fix for regions inside operation definitions disappearing
- fix for patches with more than 10 operations showing later operations as black
- quad icon now works for all themes
- previous/next icons now colored correctly in all themes
- string editors/comments now have a configurable "Max Visible Characters" to prevent low performance with too long lines
222: 18 04 19
- VL.Skia Camera 2d is not experimental anymore
- fixed pin interaction in signature view
- fixed an edge case when then node browser wouldn't show up
- fixed IOBox rendering freezes
- added many tags to VL.CoreLib to find nodes faster
- VL.Skia is referenced by default for new documents
- toggle toggles on every mouse click
- IOBox values are not applied while typing anymore
200: 15 04 19
- inputs/outputs of definitions/regions and groups can be moved (again)
- fixed problem with documents not opening anymore
- fixed file path serialization of dependencies when the path couldn't be made relative to the document itself
- fixed coloring of pads and region bordercontrol points
191: 13 04 19
- a comment that only holds a link can be right-clicked to open in the browser
- recent sketches now show in reverse order: most recent is topmost
- fix: improved recizing of nodes, regions and ioboxes
- fix: input/output indicators on pins and pads are now in sync with tooltip (again)
- fix: selected spread ioboxes can now be deleted with backspace when hovered with the mouse
180: 11 04 19
- fixed background for definition patches
- Skia ButtonBehaviour now lets you specify which buttons to listen to
177: 10 04 19
- new setting DocumentAskOnFirstSave sets whether to ask for save location on first document save
- added "Show Intro Patch" to quad menu, to recall intro patch even if it's not shown on startup
- reactivated play/pause mode visualization
- various coloring/theme fixes
- active tab is underlined (again)
- definition patches now have a hatched background
- removed RestructureDocument from patch context menu
- default count of a collection pin group can now be configured
- Skia Group defaults to 2 inputs (again)
150:
- VL.OpenCV now comes with demo patches in Help Browser!
- fixes for Skia ImageReader and ImageWriter
- added '-m' or '--allowmultiple' command line arg to allow running multiple instances side-by-side
- shortcuts are deactivated for patch when Finder box is open
- several fixes for IOBox drawing and interaction
139:
- fixes various assembly not found exceptions when using nodes of the Midi category, the Script region or binary serialization: a, b, c
137:
134:
- Info.vl in now called Intro.vl
- double-clicking .vl files will open with the already running instance
- Skia renderer goes fullscreen via F11 or Alt+Enter
- many fixes and tweaks
Apart from the promised and still missing parts, we're aware of quite some little glitches still and will update the download link above periodically. So please check back often and report your findings!
Yours truely,
devvvvs.
Patcher People!
It's been a while since the b38.1 release. But finally we're getting ready to release an update to vvvv beta. Here is the release-candidate, meaning it has all we wanted to add for beta39. We only want to give you a chance to test this with your current projects so we have a last chance to squash any new bugs, you may encounter.

Here are the highlights of the upcoming release:
General
- We get rid of the term 'alpha' and replace it with the term 'beta-preview' to be in line with gamma and gamma-preview
- Finally we ship an installer! Just a few clicks and you should have vvvv beta running.
- Optionally installs the addonpack for you.
- Still we left good old setup.exe there but renamed it to config.exe, since you don't necessarily need to run it anymore to set things up
- We're also planning to offer an offline-installer, but only for the actual release (not every preview)
- We're also keeping the .zip downloads
- For convenience, by default new patches now save to %User%\Documents\vvvv\beta(-preview)\Sketches. Like this you can quickly find your recently created patches via a new main menu entry: Recent Patches
- We've added two shortcuts to the main menu:
- Show Installed Packs: opens explorer pointing to the \packs directory
- Download Contributions: opens a browser pointing to the contributions page
- vvvv beta now supports RCP out of the box, which allows you to expose IOBoxes to control them remotely. See the helppatch of Rabbit (RCP) for details.
New nodes
- WebSocket (Network Client)
- PBR (DX11.Effects), PBRInstanced (DX11.Effects)
- PBRTextured (DX11.Effects), PBRTexturedInstanced (DX11.Effects)
- MaterialPropertiesPBR (DX11.TextureFX)
- Lights (DX11.Layer PBR)
New in VL
If you're also using VL already, good for you, because here you'll find even more goodies you will benefit from:
- Shiny Tooltips
- IOBoxes 2.0
- Regular Expression nodes
- Pingroups
- If you're looking for the Manage Nugets menu entry under Dependencies: this has been moved to the Quad menu
- and quite some more as we've listed in the gamma preview changelog
Besides those, it is important to understand that with VL you also have access to numerous more libraries that have been released recently. A lot of new packs these days come as nugets. For an overview, see VL packs on nuget.org and you can use them all in vvvv beta, via VL...
Download
vvvv beta39 x64 RC11
vvvv beta39 x86 RC11
Changelog for Candidates:
RC11
- fixes on bumpy Damper
- fixed SVGWriter
RC10
- fixes issue with girlpower\VL\_Basics\ParticleSystem not loading
RC9
- Press IOBox now releases when left button is click while right-pressing
- Fixed a bug in OSC nodes
- Dampers can now be used in loops
- fixed image tooltip
- fix on tooltip layout
- some color operation improvements
- can now create a node while linking by simply starting to type
RC8
- updated to latest VL
- removed a few unnecessary Damper versions
- fixed time step calculation of Damper (Fast)
RC7
- Installer finds path to Powershell.exe on it's own
- VL close dialog lists unsaved documents
- some minor fixes on VL Damper nodes
- fix for C# node input pins that access an empty spread
RC6
- SaveAs inside VL editor back again - node references in v4p should now get updated correctly
- Fixed a few crashes of VL serializer when dealing with object fields
- PBR nodes should show up in nodebrowser again
- SelectNodesDontScroll added
RC5
- Regions now show timings again
- Node tooltips now show timings for the current instance
- Image download from GPU will again happen in AsImage node to avoid breaking changes and potential crashes in existing patches
- installer adds vvvv folder and process to Windows Defender exceptions
RC4
- changed AppData location for nugets to \beta(-preview)_{architecture}\nugets
- removed AppData location for packs again (to be reconsidered after b39)
- in VL outboxes are working again
- installer checks and installs DX9 and VC++ Redistributables correctly
RC3
- Ctrl+P now creates new patch pointing to active patchs directory
- fixes problem with AsImage (DX11)
- fixes problem with saving a new patch to \Sketches
RC2
- adds options to register .v4p and .vl from the installer
- fixes an issue with the installer popping up config.exe unnecessarily
- fixes Ctrl+G
- fixes Keyboard (Devices Windows) Enabled pin
- fixes global references to .fxh includes for dx9 effects
So please give this release candidate a spin and be sure to report your findings, preferrably in the forum using the "preview" tag, or also just by posting a comment below.
In preparation for the Xenko game engine integration we decided to change the default math library of VL from SharpDX to Xenko. The decision was particularly easy since both math libraries have the same origin and most types and methods are identical. And thanks to the VL import layer it's easy to switch out the types, without any noticeable changes for the VL user.
What you get:
- Existing VL patches will continue to work as before
- No conversion needed when working with Xenko
- Faster matrix uploads to GPU (see below)
Trivia
We are (again) in luck with Xenko since it just so happened that Alexandre Mutel, who developed SharpDX, was a core developer at Xenko. We actually didn't know that at the time we started to work on the VL core library. We chose SharpDX mainly because it was well established, complete and open source. So it was quite a nice surprise when we browsed the Xenko source code for the first time and saw that they basically use the same math code.
Download
Here are direct links to the latest preview versions:
vvvv gamma 2019.1 preview 624
vvvv_50alpha38.2_x64
addons_50alpha38.2_x64
Technical Details
This section is only relevant for library developers.
Transposed Matrix Memory Layout
Xenko's 4x4 matrices have a transposed memory layout compared to SharpDX. This is not to be confused with transposed matrix elements (M11, M12, M13 etc.), it is only relevant when doing low-level operations with memory and pointers, such as uploading them to the GPU. The big advantage of it is, that Xenko's matrices can directly be uploaded to the GPU without the overhead of transposing them.
Changes on C# Projects
Most C# projects written for VL don't need to be changed. Only if they use the SharpDX.Mathematics nuget to work with vectors, matrices, rectangles etc.:
- Must switch to Xenko math
- Must use the new SDK style project format
In order to transition your C# project to Xenko, remove the SharpDX.Mathematics nuget and install Xenko.Core.Mathematics instead. Then change the using statements in the C# files:
//old: using SharpDX; //new: using Xenko.Core.Mathematics;
If you then get an error on compilation, your project might be in the old format. Upgrading is quite easy, it just involves changing the header and deleting most lines in the project file. Follow this guide or join our chat if you need help.
Please give the new version a spin and send us a report if anything doesn't work as before.
Happy calculations!
Yours,
devvvvs
Here we go!
As mentioned previously, an update to how tooltips look and work, was one of the two main things missing before we call vvvv gamma a 1.0 release. And they have just landed in the preview, horray!
Previously tooltips where text-only, rendered all in one style and often contained rather cryptic information. Now we have structured information that is nicely presented and we also tried to replace weird messages with human readable text where possible.
Nodes
Tooltips on nodes foremost show the nodes full name and category plus its "Summary" and "Remarks" help information in two separate paragraphs. Additionally, if available you'll see timing information, ie the amout of time the node needs to execute. Operation nodes can also show you the name of the operation they are currently executed on.


In case a node has an error or warning, we try to help you understand what's going on by answering the following three questions:
- What is the problem we see?
- Why is this a problem?
- How can you deal with it?
- In case of warnings: When can this warning be ignored?
Also, while a warning/error tooltip is visible, pressing CTRL+C copies the message for convenient pasting, eg. in the forums.

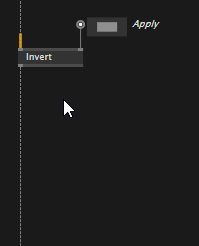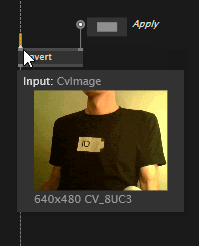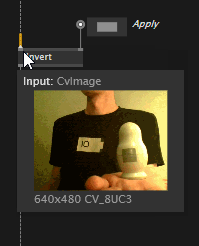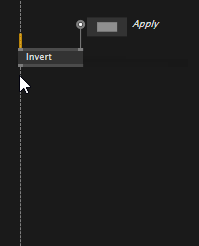
Pins
Tooltips on pins foremost show the pins name and datatype. For for primitive types (like numbers, strings, colors,...) that can easily be displayed, we also show the current value.

In cases of collections (like spread), we also show the current count and again, if the datatype is displayable, we now show up to three slices, as compared to the previously only one.

Oh, and the obvious:
Links
Tooltips on links are by default only visible, if the link has an error or warning. To get a tooltip showing on normal links, to see their datatype, press CTRL while hovering it.

Scaling
Zooming patches is nice, but we figured independent of that, we also want to be able to define the size of a tooltip. so zooming tooltips it is:

Explorer
Also the patch explorer got a bit more informative using the new tooltips.

Nodebrowser
Same goes for the nodebrowser, which should make it easier to find the right node as the summary and remarks are now much more pleasant to read.

Settings
And finally, there are a now a couple of more settings to tweak for tooltips:
- Classic: enable to go back to the old style tooltip
- Scaling: default value for the tooltips size
- ShowAdvancedTimings: make process nodes show timings for individual operations
- ShowObjects: show innards of patched objects
- ShowLocalID: mostly for our internal debugging use
- ShowMoreInfo: default state of errors/warnings with more info
- ShowOperation: which operation the node/pin/link is on
- ShowSymbolSource: which document the node is coming from
- ShowTimings: show or hide timings alltogether
- StdDelayInMilliSeconds:
A few tweaks here and there and more viewers to come for more special datatypes over time...but the biggest part is hereby done. To test, download the latest preview and then please let us know what you think in the comments.
jojojo IO,
one of the more important features for quick prototyping in vvvv always were the IOBoxes. Here is an update that finally brings the vl IOBoxes up to par (and beyond) with what you were used to from vvvv beta.
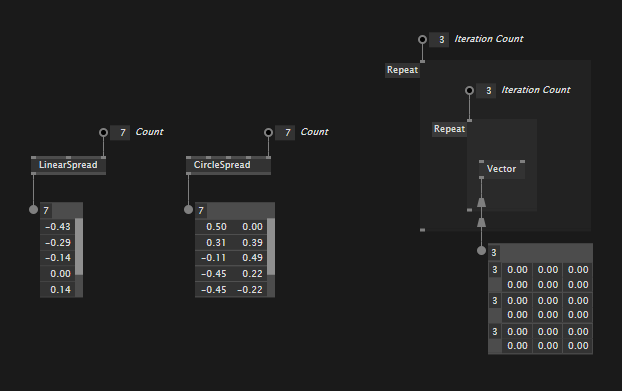
Support for Spreads
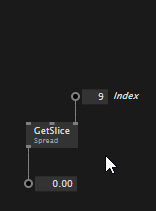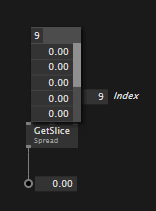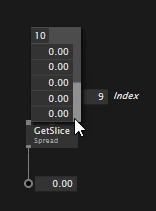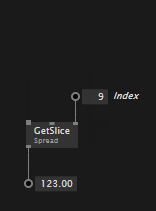
Most notably missing so far was proper support for spreads. Sorted. When creating an IOBox via "start link -> middleclick" you now always get an interactive IOBox for the supported primitive types: ints, floats, bool, string, path, color, enum, even if they are spreaded or spread-of-spreaded or...
Or configure your own, by first creating a normal IOBox via right doubleclick and then configuring its type (middleclick it) via the Inspektor to a Spread type:

Key to spread IOBoxes is that you can directly set their count, without the need to open an inspektor. By default they now show a maximum of 5 entries and add a scrollbar to show more. If you want to see more, you can change the "Maximum Visible Entries" count via the Inspektor.

To quickly modify a constant spread you can also insert/remove slices when the inspektor is active:

Same as with other editors, the spread editors also work on inputs of a node to quickly tweak values:
And you can now specify defaults for input pins that are spreads:
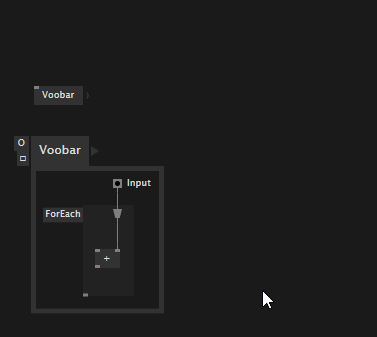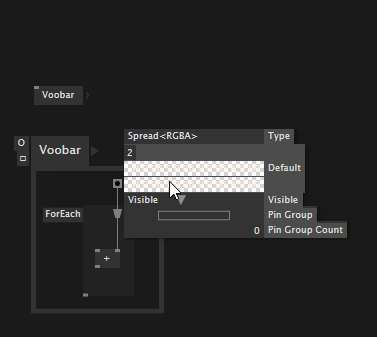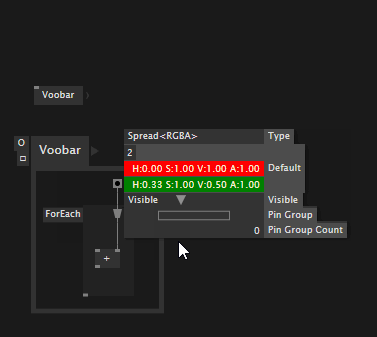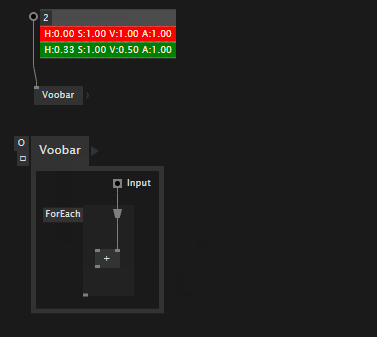
Override values temporarily
Mostly useful for numbers and bools, in vl you can override upstream values directly, by manipulating an IOBox that sits in the middle:
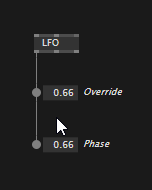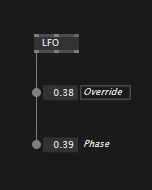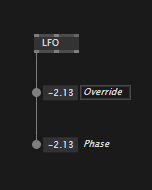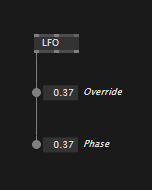
Numbers
What we're used to from beta: Entering values via formula now also works:

Vectors
Vectors now allow you to change all components at once:

Also the Inspektor now shows all properties that you get on a float IOBox, so you can now also configure e.g. a vectors precision.
Strings and Chars
Both can now optionally show non-printable characters:

Colors
Color IOBoxes now also show you transparency:

Paths
Paths finally can be reduced to smaller sizes and show proper path ellipsis, ie. preferring to keep the last part of the value visible:

Click the little O icon to open the current file/directory with their associated program. ALT+click the icon to show the file/directory in the explorer.
Matrix
For completeness:

This is it for now.. Available for testing in both latest alphas and gamma previews.
General Status
As you know, efforts have been going for the last year and a half into bringing a computer vision nodeset to VL.
The goal was to incorporate as many of the features covered by the world renowned ImagePack; contributed by Elliot Woods some years ago; while bringing in as many new features and improvements as we could.
In the winter of 2018, after setting a roadmap and having patched a decent initial nodeset, we happily announced the pre-release version of VL.OpenCV.
Since then, listening to your needs and constant feedback, we have tried to polish every corner, fix every bug, document every odd scenario, add plenty of demos and specially we tried to give you a clean, consistent and easy to use nodeset.
At this point in time, we are happy to announce that the goal has been nearly met. Most of the features available in the ImagePack made it into VL.OpenCV with the exception of Structured Light, Feature Detection, StereoCalibrate and some of the Contour detection functionality. At the same time, newer features such as YOLO, Aruco marker detection and others have been brought in for you to play with.
So what's next? Even better documentation and loads of examples!
In the mean time, here is a summary of the new things that have been brought into the package in the last couple of months:
CvImage
The new CvImage wrapper around OpenCV's Mat type allows for some optimizations, specially when dealing with non-changing images.
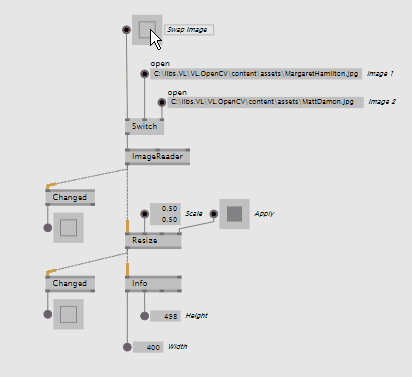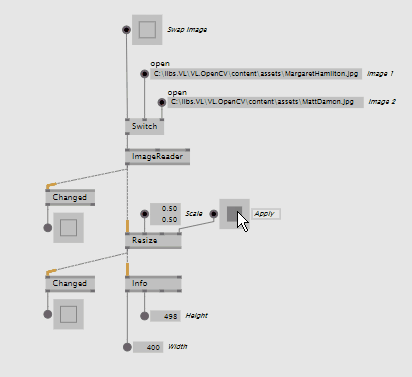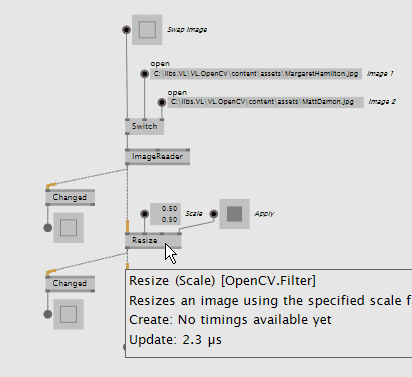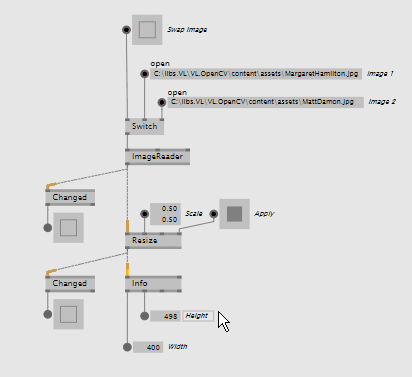
CvImage allows nodes to run only once when the image has changed, significantly reducing CPU usage
Cache Region lovvvves CvImage!
Since it is now possible to detect if an image has changed, CvImage is a perfect candidate to benefit from Cache regions.

Cache regions can now make proper usage of image inputs and outputs
Renderer
The Renderer was re-built from the ground up to improve usability and to fix bugs and issues. Title, Render Mode and Show Info features were added. Renderer also remembers its bounds on document reload.

New Renderer implementation introduces Title, Renderer Mode and Show Info pins
Histograms
Histogram analysis has been added to VL.OpenCV. A useful tool in many scenarios.

Histograms allow you to analyze pixel value tendencies per channel
Homography
Homography and reverse homography are now available in VL.OpenCV.

Homography (vvvv used only for point IOBox)
Stereo Matchers
Two new Stereo Matchers were added, these allow you to create a depth map from a set of stereo images. For more see the StereoDepth demo patch in VL.OpenCV.

Depth map obtained from a pair of stereo images
Serialization
Serialization support was added for CvImage and Mat types, allowing you to use CvImage as part of more complex data structures which get serialized with no effort. This can be a heavy operation so make sure to trigger it when needed only.
For a hands on demonstration check out the Serialization VL demo that ships with VL.OpenCV.
Breaking Changes
As part of this final effort to clean everything even further and make the nodeset consistent and properly organized, we needed to rename and move a few things around which as you can imagine means the introduction of breaking changes. We understand this is an annoying thing to cope with, but this was basically the reason why we chose to keep this pack in a pre-release state until we felt confident with its structure and approach.
In summary yes, you will get red nodes when you upgrade your VL.OpenCV projects to the latest version, but in most cases it should be as easy as to double-click and find the node in its new category.
An exception to this are the nodes that got renamed, which we list below:
- Reader (Intrinsics) -> IntrinsicsReader
- Reader (View Projection) -> ViewProjectionReader
- Writer (Intrinsics) -> IntrinsicsWriter
- Writer (View Projection) -> ViewProjectionWriter
- GetByteArray -> ToByteArray
- GetValues -> ToValues
- GetValues (Custom) -> ToValues (Custom)
- FiducialTracker -> FiducialDetector
- Update (FaceRecognizer) -> FaceRecognizerUpdate
- VideoFile (Append) -> VideoWriter (Append)
- VideoFile - VideoPlayer
- Merge -> Join
Summarized Changelog
General
- Introduced a new wrapper for Mat called CvImage
- Cache region additions to improve performance on non-changing Images
- ImageReader re-implementation
- Renderer re-implementation
- VideoIn re-implementation
- Reintroduced "Supported Formats" output pin on VideoIn node
- Upgraded to VL.Core 0.95.37
- DirectX/OpenCV transformation documentation and cleanup
- Added Blocking, Reactive and HoldLatestCopy versions of VideoIn node
- Added Blocking and Reactive versions of ImageReader node
- Reimplemented Extrinsics as a data type
- Stabilized VideoFile Source node and moved from Experimental into Sources
- Added Serialization support for Mat type
- Added Serialization support for CvImage type
New in VL
Nodes
|
Demos
|
New in vvvv
Nodes
|
Demos
|
Remember that in order to use VL.OpenCV you first need to manually install it as explained here. Also, until we move away from pre-release you need to use the latest alpha builds.
We hope you find good use for this library in your computer vision projects and as always, please test and report.
Up until now VL had a rather rudimentary support for pin groups. Only nodes following a certain pattern had the option to have a dynamic amount of input pins. For simple nodes like a plus or a multiply this worked out fine, but for others it either felt like a hack or it was simply impossible to use at all. A node having a dynamic amount of outputs was never supported at all.
Pin Groups by Index
This all changes now by introducing proper support for pin groups. So let's jump right into it and have a look at the definition of the very famous Cons node:

As we can see the pin inspektor is showing one new entry called "Pin Group". This flag has to be enabled obviously. Then we annotate the pin with type Spread. This creates pins with the name "Input", "Input 2", "Input 3" etc. on the node.
If we now look at an application of the Cons node we can already see a couple of nice new features:

- It's much faster. To build the input spread it can make use of a spread builder allocating the needed memory in one go, compared to the old Cons node which concatenated one spread after the other, leading to a total of 8 copies.
- The returned spread will stay the same as long as the inputs stay the same. This is done by keeping the generated spread for the input group in an internal field. When building up the new spread each slice will be compared to with the one from before. And only if one of those slices change a new spread will be allocated.
Pin groups are not limited to inputs, they also work for outputs which brings us to a new node called Decons - deconstructing a spread into its outputs:

Pin Groups by Name
Cons and Decons are examples of using a pin group as a Spread. But there is another variant where the group gets annotated as a Dictionary<string,*>. Instead of addressing the pins by index, they get addressed by their actual name. Let's have a look at two other new nodes again called Cons and Decons but residing in the Dictionary category:

Pins can get added as usual with Ctrl - +, but what's new is that those pins can be renamed in the inspektor UI giving us the ability to quickly build up dictionaries.
The patch of the Cons building up a dictionary compared to the one building up a spread only differs in the type annotation of the input pin.
Apart from Spread and Dictionary the system also supports pin groups of type Array, MutableArray and MutableDictionary. According Cons and Decons nodes can be found when enabling the Advanced view in the node browser.
Creating Pins from within a Patch
So far the pins of a pin group have always been created by the user interface of the patch editor. Things get really interesting though when creating them from within the patch itself:

Imagine the string being an expression of some sort generating inputs for each unbound variable. The possibilities are endless :)
The nodes needed to create and remove pins can be found in the VL category after adding a reference to VL.Lang - the patch from the gif above can be found in the help folder of the VL.CoreLib package.
More information on those nodes will be covered in an upcoming blog post. Until then you can try these new pin groups in our latest alpha downloads and happy patching,
yours,
devvvvs
Since a while, VL comes with the idea that you can organize node and type definitions in your VL document.

But now, we want to give you back another, alternative way to look at things - an organization structure, which is more intuitive and also well known from vvvv beta: The application side of things...

And also, we did this in reaction to the feedback we got from Link festival:
You want to be able to navigate the running object graph, where it's about the instances of patches, not about their definitions. You want to be able to navigate into a running patch and see the values that flow in this instance, not in another instance of the same patch...
Also, typically you approach your project top-down and just add more details to it since this is the basic idea of rapid prototyping: patching a running system that you incrementally grow and modify.
So we took the chance to shift the focus a bit so that in VL you again get confronted with the application side of things first.
The Application Side of Things
This is what you know from vvvv beta: a patch can contain a sub-patch - you navigate into it and inspect the values flowing. You go outwards - to the caller - via "Ctrl-^". With the ^-Key we actually refer to a key at a certain position on the keyboard.

In VL this now is just exactly the same. Navigating into a process node shows you the right values. Ctrl-^ brings you back to the caller. So you are basically navigating the living node tree of the application. In VL it's been hard to think in these terms, but now it's the default. We also made sure that this works when navigating between vvvv beta and embedded VL nodes.
Also, try to use the back and forth mouse buttons if you happen to have a 5-button mouse. Ctrl-MouseBack will bring you to the calling patch and Ctrl-MouseForth will travel back into where-ever you were coming from.
Every VL document comes with an Application patch, which will open by default. You can start patching right away. A bit as it is like in vvvv beta.
Patching top-down never has been easier. Creating an Ape simulation from scratch:

You can run many applications at the same time, e.g. several example patches in addition to your project app. The application menu lists all documents that actually make use of the application patch.
The Definition Side of Things
Definitions in vvvv beta basically correspond to the .v4p files, in VL you can have more of them per document.
Library developers or more advanced users will of course still want to organize types and nodes and approach them from the definition side. This is like saying "There is one idea of a wheel, but if you feel like you can instantiate three of them".
For an overview of the definitions, each document comes with a separate Definitions patch - basically what's been the document patch.
Here you see what happened during patching top-down: on the definition side, we now have two Processes.

That's where you would from now on also place your Classes, Records...
Navigation within the current document structure works with Ctrl-Shift-^, Ctrl-Shift-MouseBack, Ctrl-Shift-MouseForth.
When navigating into a patch like that you will see some instance of the patch or maybe none, if none is instantiated or currently running. In this case, you will not be able to see any values.
If the patch is not yet inspecting a particular instance it will wait for the moment an instance gets executed and then attach to this particular instance.
Some more minor cleanup
We took the chance to clean up some bits in the node browser and the patch explorer as well.
The application patch e.g. now doesn't offer confusing options, but basically only shows the properties stemming from pads, the Process Node Definition now is called that way (was "Order"), Process Nodes in the node browser look a bit like process nodes in the patch, choices like "Input", "Node" appear at the top of the list of choices in the node browser...
That should be it for now!
Thanks, yours devvvs
anonymous user login

Shoutbox
~2d ago
~2d ago
~6d ago
~14d ago
~22d ago
~1mth ago
~1mth ago
~1mth ago