
Blog
Blog-posts are sorted by the tags you see below. You can filter the listing by checking/unchecking individual tags. Doubleclick or Shift-click a tag to see only its entries. For more informations see: About the Blog.

Skia is a modern and fast 2d rendering library. As usual, we stand upon the shoulders of giants when making this functionality available to you: the core Skia technology and the .Net binding "SkiaSharp". The VL.Skia package aims to make all of this functionality available within VL in an easy-to-use high-level node set.
You now can have the first glimpse on it. From the start, it comes with a nice stack of tutorials and example patches. This package is done for vvvvbeta37.
Here is a rough overview of what the key concepts are:
Layers and RenderersJust like known from vvvv the main idea is that layers can be grouped and can be connected to a renderer to draw them. Most Layers come with a Bounds input OR Position and Size and Anchor. We offer different renderers:
|
 |

|
Shaders, Filters, and PathEffects are all properties of Paint. 1000 words wouldn't be enough to describe what you can do with them. You probably just need to play with them a bit. |
 |




How to install
In order to use this library with VL, you have to install the NuGet that is available via nuget.org. For information on how to use NuGets with VL, see Managing NuGets in the VL documentation. In short, navigate via document menu to Dependencies -> Manage NuGets -> Commandline and then type:
As long as we don't have an example browser here is how to get them via windows explorer:
Drag & drop an example patch onto vvvv or VL. For closing the example use the X on the renderer or hit Ctrl-F4 on the VL patch.
Happy exploring!
Yours,
Devvvvs
Serialization in VL has drastically been simplified by introducing two new nodes called Serialize and Deserialize in the category System.Serialization.
Let's first have a look at two basic examples:


Serialize takes any value and serializes it into a XElement while Deserialize does the exact opposite, it takes a XElement and turns it into a value of the requested output type.
As you can see from the screenshot the resulting string is very short and contains only the mimimum amount of data. It achieves that tidyness by only serializing user defined properties, skipping properties which have the default value, making use of XML attributes, putting collections of primitive values into comma separated strings and adding type information only when necessary.
When deserializing the system will try to apply the serialized content on the instance to be created. This makes it very resilient to future patch changes as adding or removing properties and to some extend even changing the type of a property will just work.
Serializers are provided for all primtive types (Boolean, Integer32, Float32, etc.), collection types (Array, Spread, Dictionary, etc.), commonly used imported types (Vector2/3/4, Matrix, Color, etc.) and most importantly all patched types. If a serializer should be missing for a certain type either report it to us or keep on reading to the next section where you learn how to patch (or write) your own serializer.
Paired with the new files nodes serialization to disk is straight forward:

That's basically all there is to know from an end-user perspective. You can try these new nodes in the latest alpha versions.
Writing a custom serializer
Even though VL ships with serializers for the most common types the situation could still arise where a custom serializer has to be written - either because it's simply missing for the type in question or one is not satisfied with the output of the already existing serializer.
Creating a custom serializer consists of two steps
- Patching (or writing in C#) the serializer by implementing the ISerializer<T> interface using the advanced Serialize and Deserialize nodes working on the SerializationContext
- Registering that serializer using the advanced RegisterSerializer node inside the static RegisterServices operation (more on that in an upcoming blog post)
Here are two screenshots of the above from an example implementation which can be found in the VL.CoreLib/help/Serialization.vl file:


We're looking forward to your feedback.
Happy serialization!
Dear patcher,
as an avid vl user by now you've understood that in vl there are different kinds of patches. While colloquially we just call them all patches for simplicity and because they all allow you to patch in them, we can easily distinguish two main types of patches:
- Datatype Patches: patches defining a process node and/or datatype
- Structural Patches: patches that only help you structure your programs
While datatype patches more resemble what we had in vvvv, structural patches are new in vl. We just reworked this part a litte and ended up with 3 structural patches which make things much more clear:
- Group
- Category
- FullCategory
But before we go on let's make sure we are on par regarding the term "Category":
Obviously. (Yeah, just wanted to make sure)
What we had so far was a not so clear mix of all three. Let's see what we have in latest alpha:
Group
Group patches simply allow you to create more space in a patch by opening a new canvas. The groups name is merely used for human readability, vl doesn't care about it at all. Create a group by typing "group" in the nodebrowser. Groups is what you will be mostly using in your daily project-patching work.
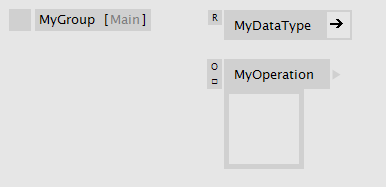 Inside a group patch
|
 Group patch from the outside
|
Category
A Category patch looks quite similar to the group, only its name has a meaning: The name appends itself to the category of its parent patch. That way you can build up any category hierarchy, that you then see in the NodeBrowser. Multiple category levels are allowed with dot notation. e.g. MyCat1.MyCat2.
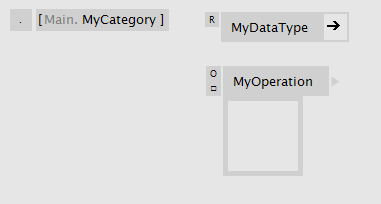 Inside a category patch
|
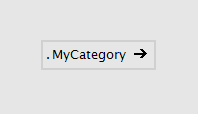 Category patch from the outside
|
Full Category
A Full Category patch is similar to the Category patch, only that it doesn't add its category to the parent. By that you can place nodes in any category, regardless of the parent patch. It's considered bad practice to do that, but is useful to add nodes to an existing category like Collections.Spread, for example. Multiple category levels are allowed with dot notation. e.g. MyParentCat.MySubCat.
 Inside a full category patch
|
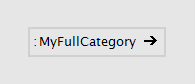 Full category patch from the outside
|
Each vl document can directly start a category, which you can define in the angular brackets in the top left corner of the document patch.
Changing the Patch Type
You can easily convert a group patch into a category patch and vice versa by the patch type enum. Note how the label changes and represents the actual category structure:

Setting Categories on Node-Definitions
As if the above didn't offer enough options already there is one more way to specify a category for an operation or a datatype definition:

Happy node sorting!
Some things take a while longer...
Planned since vvvv pre-beta1 we're happy to finally bring you:
Frames
Patches tend to do different things all at once and when looking at them it is often not clear at first sight which part of a patch does what. We have comments to add a few words at certain spots but those fail when we'd like to point at a group of nodes that do a certain thing. So the idea is to have a visual element we can place in a patch to frame a group of nodes and mark them with a color and label. This will help us to better structure and document large patches.

Frames are always in the very back of everything. They don't contain any other elements and they cannot be contained in other regions. They are mere visual elements and don't interfere with the functionality of a patch in any way.
To show/hide all frames in a patch at once, press CTRL+ALT+F.
To frame a bunch of selected nodes, press ALT+F.
Screenshots
Besides being structural elements, frames also allow you to take screenshots easily and repeatably. We're using this e.g. to automate generating screenshots for our documentation...
Here is how:
- Press the Printer button to make a screenshot, then rightclick it to see the captured file in explorer
- Alternatively press CTRL+2 to take a shot of the selected frame
- Press CTRL+5 to take screenshots of all frames in a document at once
To create a quick screenshot of an area without even creating a frame, simply press S while making a selection. This will copy the screenshot to the clipboard (so you can simply paste it into the chat or a forum reply) and also place a .png next to the current .vl document.
Recordings
Apart from single screenshots you can also record an animated gif of the area of a frame, here is how:
- Press the Record button to start a recording, the same button again or ESC to stop it
- Alternatively toggle CTRL+4 to start/stop recording the selected frame
Note that the resulting .gifs are quite large. This is a known problem that shall be fixed at some point.
Screenspace Frame
One more: In case you want to make a recording that includes panning or zooming in the patch you can create a frame in screenspace:

Here is to inform you about an update to general File input/output in VL available for testing in latest alphas today. Introduced 1.5years ago we've now completely reworked this from the ground up with the things we've learned so far.
Blocking
We noticed that even though obviously you'll often want file io to be non-blocking, there are cases where blocking makes sense. So we now give you the following:
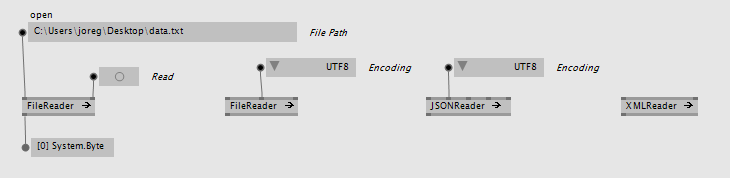
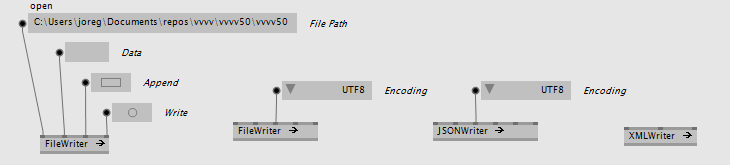
These are the most simple to use, very close to the comparable vvvv versions, only without error reporting, which we explain below.
Non-Blocking
In the case we want to have our file io non-blocking we learned that most likely we don't only want to load the file but often also do some kind of "transformation" to the data before it is used further in the patch. Most likely this transformation should also be non-blocking and we only want to be informed when that part is done as well. Introducing:

Instead of returning the actual data of a file, those readers return an Observable<Data> which allows you to do some further processing to the data before you get access to it in the patch using a HoldLatest node. For more information on working with observables see the chapter Reactive.
The writers in turn also take an Observable<Data> and write whenever new data is pushed through the observable. Like this you can e.g. write data received from an input via an observable directly to a file without ever touching the mainloop:
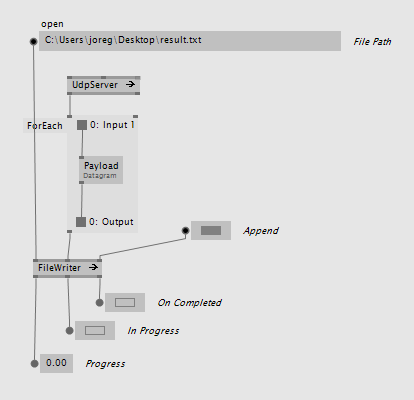
Naming Convention
While in vvvv we had different names for file accessing nodes, like: Reader (Raw), FileTexture (EX9.Texture), XFile (EX9.Geometry Load), MP3Parser (File), ... we decided on a new naming scheme for VL:
- all readers end on "Reader"
- all writers end on "Writer"
- the node is prefixed with a hint at the file-format it handles, like XMLReader, JSONReader
- more generic readers that don't read a specific format are called more generically, like FileReader, ImageReader, ..
Like this, typing "reader" or "writer" in the nodebrowser, you'll be guaranteed to find all available readers and writers.
Error Handling
Reading or writing files can go wrong for different reasons and the system needs a way to inform you about this. Previously, error handling of reader/writer nodes was inconsistent. Some ignored errors, others reported "Success" or returned an "Error Message". Having realized error-handling has to be supported on a higher-level than individually on every node, we have now removed all error handling from those nodes.
Now what? Right, so the first thing you need to know: If an error occurs at runtime it will be catched by vl and the node will go pink, informing you of the problem. Often this is enough.
In case you want to react to an error in your patch we again have to differentiate between the blocking and non-blocking case:
Blocking
The solution for the blocking case involves using the experimental Try [Control] region and looks like this:

Non-Blocking
In a non-blocking scenario you can use the HoldLatestError [Reactive] node like this:


Growing a consistent library of nodes and presenting it in a clear way in the NodeBrowser is one of the great challenges we are facing. For the upcoming release we made this our focus: Clean up the core library vl offers and add new features to the NodeBrowser for easier browsing. So here is what you get:
Filtering by Aspects
The NodeBrowser got a couple of new toggle buttons that let you filter for different aspects. Aspects include "Advanced", "Experimental", "Obsolete"...
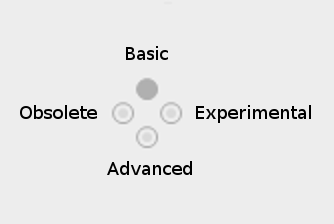
Button layout: Time goes from left to right (Obsolete -> Experimental), high level to low level from up to down (Basic -> Advanced).
By default you see all normal nodes, ie. those without any aspect. This is what we consider the 80% most important nodes for the casual user. Browsing the categories with this setting should give you a good, not too overwhelming overview of what functionality is available. For example it excludes all nodes using types we consider advanced, like Float64, Integer64,... mutable collections (like Array, ..) and often nodes that we hope you'd not have to use every day.

Advanced
If you're looking for a node and it doesn't show up you can enable the "Advanced" aspect. This will include many more nodes. Obviously the distinction between normal and advanced is very subjective and will vary widely for different users and use-cases. So we are aware that there is room for debate and nodes may be moved between normal and advanced in future versions. The good thing about this is that such a move between aspects never breaks any patches!
You can toggle this filter button with the TAB key.
Experimental
Includes nodes that we haven't yet fully committed to. Use those at your own risk. We don't guarantee that they'll still work the same in future versions
Obsolete
Includes nodes that we only still ship to not break existing patches. Don't use them in new patches. Most likely there is a better version of the node available already.
Internal
Nodes can have the "Internal" aspect set, meaning they are only visible within their .vl document but don't get exposed. So if another document references the first one, it will only see nodes that are not Internal. Using the toggle you can hide those internal nodes from the NodeBrowser to have a view on the node set that other documents would see.
Defaults
The default setting for the filter buttons for Advanced, Experimental and External on startup of VL can be adjusted in the settings.xml file. If you are working a lot with .dlls from c# projects and you need to restart often, you probably want to enable the 'External' button by default.
Assign Aspects to Nodes
For information about assigning nodes to aspects, see this gray book section and feel free to open a thread in the forums for specific questions.
Filter externals
When referencing an external .dll it often leads to a very large number of extra nodes in the NodeBrowser. Using the "External" toggle you can decide whether to see those in the NodeBrowser or not. Also the NodeBrowser is faster when it doesn't have to deal with those.
You can toggle this filter button with the SHIFT+TAB keyboard shortcut.
Stateful Nodes
Aka process nodes got merged with their stateless siblings with the same name. If there is a process node and a stateless node with the same name you get a "..." icon in the NodeBrowser and after clicking on it you have to choose which one you want.
More Collections
This category got the most rework so it's worth to mention its specific changes here.
VL encourages the use of immutable collections because they work very well together with the data flow paradigm. But when working with .NET libraries you often have to deal with mutable collections, so we now provide all commonly used collections of the .NET framework!
In general we try to do as little renaming as possible when importing data types. But for the collections we took the liberty to do the following renamings from the original ones:
- ImmutableArray -> Array
- ImmutableDictionary -> Dictionary
- ...
- Array -> MutableArray
- Dictionary -> MutableDictionary
- ...
All interfaces for collections moved into the Interfaces sub-category and we introduced a Common category that contains data types and nodes that are used together with collections like KeyValuePair or CustomEqualityComparer.
Rectangle Improvements
The nodes to create rectangles are much more flexible now. You can specify the size of the rectangle and an anchor position. Depending on the enum input Anchor, the position gets interpreted as any one of the significant points in a rectangle, like TopLeft, Center, BottomRight, ... Also the split node got this enum to specify which point of the rectangle the output position should be.
Additionally there is a node to create a rectangle spanned by two points and one to create a rectangle by the coordinate values of it's edges.
We also added Inflate and Scale nodes. Inflate can offset the rectangle edges in each direction by specific amount and Scale multiplies the size of the Rectangle in each direction. Both nodes come with version Centered and Uniform which assign the same value to the horizontal and vertical direction or the same value for all directions.

Easier switch from Adaptive to specific
Some nodes (like the +,..) that you place in a patch are not tied to a specific type (like Float32) unless you make a connection to them. This is a very useful feature in vl and works 99% of times. Sometimes though you are smarter than the compiler and you want to specify to use a concrete implementation. In this case, after placing the node you now simply have to double click it to get all available options and chose one of those.
Destroy is now Dispose
In general we're planning to stick as close as possible to the naming in the .NET world. This will make VL more inviting for external developers to join and also makes documentation more easy to find. Therefore we decided to rename "Disposable" back to "IDisposable" and "Destroy" back to "Dispose".
As always, head over to the alpha builds and report your findings.
Enjoy the new order and happy patching!
yours,
devvvvs
just because!
since we can, the addonpack is now shipping with 4 new nodes:
- HTMLTexture (DX11.Texture String CEF)
- HTMLTexture (DX11.Texture Url CEF)
- HTMLView (Image String)
- HTMLView (Image Url)
What happened here is that the original EX9 based HTMLTextures have been replaced by the more generic HTMLView (Image) nodes which can easily be used for both EX9 and DX11 via the respective UploadTexture nodes introduced recently. So the EX9 and DX11 variants of the HTMLTexture nodes are now mere modules wrapping HTMLView -> UploadTexture.
The 'CEF' in the version for the DX11 modules is to have them distinguished from the also available contribution HTMLTexture (DX11) by gumilastik, with the same name, which is internally using a different backend than CEF. So horray, more choices for you!
Just in case you wonder: Obviously the DX11 variants still require the DX11 Pack to work!
And while at it we also updated the underlying backend to reflect Chromium 66.0.3359.117
Bonustrack:
With the Image nodes you can also pipe websites into the recently introduced VL.OpenCV. This maybe quite special interest but i'm sure one fine day someone will need to do exactly that:
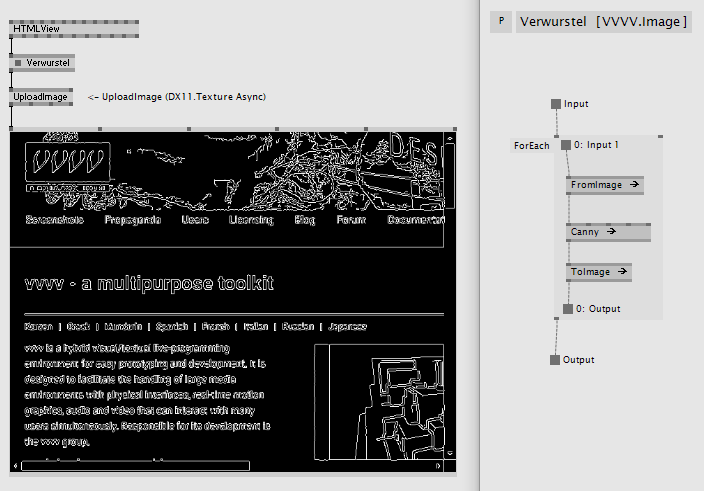
Available in latest alphas now. Please test and report your findings!

Welcome dear patchers to a new episode of devvvvs giving you control over your PC mainboard.
When you work in vvvv or VL the evaluation of your patch is automatically driven by a mainloop. It executes the nodes in your patch (usually) 60 times per second and by this allows changes to happen in your patch over time.
If you have a look at the PerfMeter in a renderer with a mainloop timer without any tweaks you will see lots of flickering like this:

Those flickers indicate that the time between two frames of the mainloop is changing a bit every frame. In an ideal world those flickers would not be there and the time between two frames would always be the same. An unstable mainloop like this creates jitter in animations, drops video frames and lets the visual output of your patch look less smooth.
It's quite a difficult task to get high-precision timer events on a modern computer architecture. Timers and me go way back to the early vvvv days at MESO when i worked on the vvvv mainloop and the Filtered time mode. Since then we could improve the vvvv mainloop time stability quite a bit by doing tricks like changing the windows system timer resolution and introducing a short busy wait phase at the end of the mainloop. The result of this work looks like this:

The experience gathered from the vvvv mainloop improvements is now available in the VL library, so you can build your own sub-mainloops.
But why would you need your own timer at all if you have a good mainloop already? There are a few reasons:
- Have a second mainloop on a different thread to split performance or don't block the mainloop
- Process something at a slower rate as the mainloop to save performance, e.g. web requests every few seconds
- Process something at a higher rate as the mainloop, e.g. output to a micro controller or servo motor
- Run parts of your patch in it's own mainloop to avoid blocking user input from vvvv
General Node Design
In VL the patch of a process node by default has a Create and an Update operation. Create gets called once an instance of the process is created and Update gets called periodically by the mainloop. In this process node patch you can place other process nodes that 'plug into' those two operations by placing their own Create on the Create of the surrounding patch and their Update on the Update of the surrounding patch.
This is the same for stateful regions like ForEach [Reactive], only that the Update of the ForEach region doesn't get called automatically by the surrounding patch but gets called by the events of the incoming observable. More on that in this blog post: VL: Reactive Programming
There are many sources of observable events. For example Mouse, Keyboard and other input devices as well as AsyncTask or MidiIn. The timer nodes work in the same way. The output is an Observable that is on a new thread and either sends the frame number (for the system timer nodes) or a TimerClock (for the MultimediaTimer or BusyWaitTimer). A patch would look like this:

The use of observables also makes it easy to swap one timer for another if neccessary.
Basically there are 3 ways to setup timers in windows and now VL has them all!
System Timer
This is the most common timer but it usually only has a precision of 16ms. It can be used for recurring events when accuracy is not the most important issue and the interval is in the seconds range or a higher millisecond range. Nodes that use these timers are for example Interval and Timer in category Reactive:

Multimedia Timer
This is a dedicated timer for applications that do video or midi event playback. It is fairly accurate to about 1ms and doesn't need much CPU power. So it can be used for most time critical scenarios. To use this timer, make sure you enable the Experimental button in the VL node browser and create the node MultimediaTimer:

So that's nice, but it has two little draw backs. You can only specify the period in whole milliseconds and as you can see there is still some flickering in the measured period times. The flickering is well below 1ms but still, we can improve that:
Busy Wait Timer
Since its possible to measure time with high accuracy, one can write an infinite loop that always checks the time and executes an event once the specified interval time has passed. This timer always uses 100% of one CPU core because it checks time as often as it can. But hey, how many cores do you have these days? With this method you can achieve precision in the micro second range, which is insane!
If any patch processing is happening on the timer event, the power of your core is of course shared with the busy wait. Just make sure that the processing doesn't take longer as the specified period:

This timer has an option to reduce CPU load for period times that are higher than the accuracy of your system timer. You can specify a time span called Wait Accuracy. This is a time span before the desired end of the period that specifies when the busy wait phase should start. Before that time the timer is set to sleep for 1ms periodically. 16ms is a safe value, but you can decrease it until the Last Period starts to jump in order to reduce CPU load even more.

Threading
Both the MultimediaTimer and the BusyWaitTimer start their own background thread with priority AboveNormal. The thread priority setting might become an input pin in the future.
So now download latest alpha, enable the Experimental button in the VL node browser and give it a shot. If anything unexpected happens, let us know in the forums.
yours,
devvvvs
computervisionados!
we're starting to collect the fruits of our hard efforts of making it easy to use thirdparty libraries. please give a warm welcome to VL.OpenCV
What the?
remember the amazing ImagePack initiated by @elliotwoods years ago? VL.OpenCV is essentially the same, only for vl: a collection of nodes for computer-vision tasks based on the industry standard library OpenCV.
OpenCV is a vast library with an endless number of interesting features. elliot back in the days did a great job in hand-picking some of the most interesting ones and wrapping them into easy to use nodes for evvvveryone.
meanwhile OpenCV has progressed and so we thought we'd give it a try and make it accessible for everyone in vl. watch this first episode of vvvvTv where ravazquez who has been working on this for the past 2.5 months, explains how you can use the prerelease package today.
Status
if we haven't missed anything, most of the functionality you know from the ImagePack should already be available, except some special video input devices, StructuredLight and FeatureDetection stuff but on the other hand already much more:
so we have:
- sources: ImageFile, VideoFile, VideoIn (Directshow)
- sinks: ImageFile, VideoFile
- filters: Blur, EdgeDetection, Average, FrameDifference...
- different background substraction options
- optical flow
- camera/projector calibration
- trackers: contours, face recognizer, houghlines, object detection (via haarcascades), different 2d tracker options
- ar marker tracking and pose estimation
- utils: Info, CountNonZero, FindNonZero, Resize, Crop, Insert, Split, Merge, Delaunay, Voronoi,...
and most of the nodes and pins come with documentation in the tooltips!
Threading
as opposed to the ImagePack, this library is completely free of the complexities of threading. instead a user can use the threading regions of vl to define their own threading. while this indeed puts a bit more effort on the user we hope that the flexibility in dealing with their own threading outweighs the cons of this.
Next
the library is open for everyone to contribute. since it is mostly done in pure vl, with hardly any c# written, it is quite accessible for everyone to extend. so please do so and best join us in the chat to discuss matters when they arise.

helo evvvveryone,
it is happening: beta36 is scheduled for a release in early february. we're quite confident with the state of the new features we've added and would like to ask you to give it a final spin with the release-candidates as listed below. please open the projects you're currently working on and see if they run as expected. if not, please let us know in the forum using the alpha tag.
Release Highlights
since the dawn of vl, vvvv has become increasingly more powerful. we see initial proof in the works of schnellebuntebilder and intolight who are using the combination already to their advantage. it allows them to create projects of a complexity that would have been very hard if not impossible to realize with vvvv alone.
so far though, vl could only be used for IO and logic tasks. anything related to rendering was still in the hands of vvvv DX9/DX11 only. with beta36 we're introducing a new bridge that will allow you to prepare textures and buffers with the convenience of vl features and hand them over to vvvv using a new set of nodes. have a look at \girlpower\VL\DX\DynamicBuffersAndTextures.v4p to see how this works! and here are some more highlights:
VVVV
|
VL
|
for an in depth list of changes have a look at the changelog.
Download
|
64-bit vvvv (beta36_rc15) addons (beta36_rc15) 32-bit vvvv (beta36_rc15) addons (beta36_rc15) |
VL documents you save with these candidates will not open anymore with beta35.8!
|
if you have the feeling that this release will not have anything for you, we'd only partly agree. true, maybe not directly. but we'd like to point out that what's hidden behind the unpretentious bullet point "Use .NET Libraries and Write Custom Nodes" listed under vl above can conservatively be understood as a bombshell. it means that anyone now has access to a vast range of .NET libraries in vl and therefore can also use those in vvvv. while this may exceed your personal abilities, it lowers the barrier to contribute to vvvv/vl in general by far and if we get this communicated right, this should be a win-win for evvvveryone. so tell your .NET developer friends about this..they should understand the implications.
at the same time this makes it easier for ourselves to now start building more interesting libraries for vl, which in turn will be a win for all vvvv users as well. hope this makes sense..
but now we wish you all some happy holidays and are waiting for your feedback on the candidate!
anonymous user login

Shoutbox
~6d ago
~6d ago
~7d ago
~20d ago
~1mth ago
~1mth ago
~1mth ago
~1mth ago
~1mth ago
~1mth ago