
VL: Improved File IO
Here is to inform you about an update to general File input/output in VL available for testing in latest alphas today. Introduced 1.5years ago we've now completely reworked this from the ground up with the things we've learned so far.
Blocking
We noticed that even though obviously you'll often want file io to be non-blocking, there are cases where blocking makes sense. So we now give you the following:
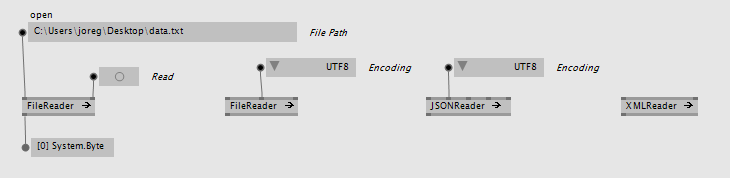
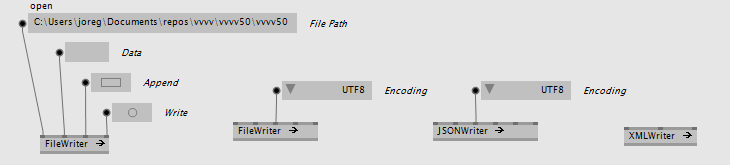
These are the most simple to use, very close to the comparable vvvv versions, only without error reporting, which we explain below.
Non-Blocking
In the case we want to have our file io non-blocking we learned that most likely we don't only want to load the file but often also do some kind of "transformation" to the data before it is used further in the patch. Most likely this transformation should also be non-blocking and we only want to be informed when that part is done as well. Introducing:

Instead of returning the actual data of a file, those readers return an Observable<Data> which allows you to do some further processing to the data before you get access to it in the patch using a HoldLatest node. For more information on working with observables see the chapter Reactive.
The writers in turn also take an Observable<Data> and write whenever new data is pushed through the observable. Like this you can e.g. write data received from an input via an observable directly to a file without ever touching the mainloop:
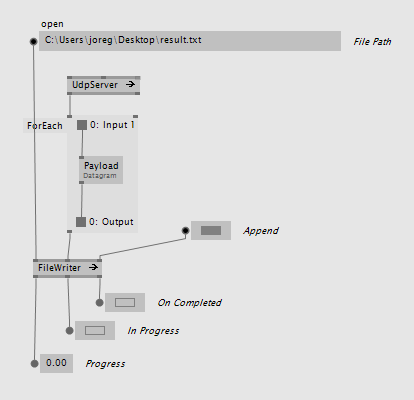
Naming Convention
While in vvvv we had different names for file accessing nodes, like: Reader (Raw), FileTexture (EX9.Texture), XFile (EX9.Geometry Load), MP3Parser (File), ... we decided on a new naming scheme for VL:
- all readers end on "Reader"
- all writers end on "Writer"
- the node is prefixed with a hint at the file-format it handles, like XMLReader, JSONReader
- more generic readers that don't read a specific format are called more generically, like FileReader, ImageReader, ..
Like this, typing "reader" or "writer" in the nodebrowser, you'll be guaranteed to find all available readers and writers.
Error Handling
Reading or writing files can go wrong for different reasons and the system needs a way to inform you about this. Previously, error handling of reader/writer nodes was inconsistent. Some ignored errors, others reported "Success" or returned an "Error Message". Having realized error-handling has to be supported on a higher-level than individually on every node, we have now removed all error handling from those nodes.
Now what? Right, so the first thing you need to know: If an error occurs at runtime it will be catched by vl and the node will go pink, informing you of the problem. Often this is enough.
In case you want to react to an error in your patch we again have to differentiate between the blocking and non-blocking case:
Blocking
The solution for the blocking case involves using the experimental Try [Control] region and looks like this:

Non-Blocking
In a non-blocking scenario you can use the HoldLatestError [Reactive] node like this:

- 1
anonymous user login

Shoutbox
~53min ago
~6d ago
~6d ago
~7d ago
~20d ago
~1mth ago
~1mth ago
~1mth ago
~1mth ago
~1mth ago
Wow, thats really awesome! Finally consistent methods of handling files and easy to find names. One thing I am never sure about and maybe should be an options for the writers, is whether or not the Writer also creates the directories or not. Can I just give it a path and it will create the folder structure if it doesn't exist or not? Would be nice to have an option for "create directories", so I can either have them be created during writing if they dont exist or if disable it throws an error like "target directory doesn't exist". What do you think? I can see both cases being handy depending on what you want to do.
Gut! How about Streams?
also big up for the try region which could be worth a separate post.
@seltzdesign
Good point, we changed the file node used by all the file writer nodes so it creates the directory if it doesn't exist yet and a new file is requested. That's indeed the much better default. We didn't add an extra pin for it though in order to avoid cluttering the nodes with rarely used pins - well at least as long as not proven otherwise.
@milo
The node set to work with System.IO.Stream will be updated/added at a later point. And yes the try region and error handling in general is a big topic where we still have to deliver. Once we get to a point where we say it's nice to work with a blog post / documentation will follow of course. Simply wasn't the focus for the upcoming release.