
gregsns notebook
This page is viewable for Admins and Editors only.
This page is viewable for Admins and Editors only.
This page is viewable for Admins and Editors only.
This page is viewable for Admins and Editors only.
old scribbles
My Favourite VVVV Topics
- Portierung
- Graphoptimierung
- Multidimensionalität
- Boygrouping auf Messages umstellen
- Fehlerlogging
- GUI weiterdenken / Alternative Views
- Timeline
- Hierarchische Strukturen abbilden / Casts
- Presets / Combinations
- Mainloops, Multithreading
- Knotenordnung, Knotenauswahl, Polymorphie, Tagging
Ideale Neuimplementierung des Graphen:
Scheduling (Mainloop)
Ziele:
- Ermöglichung von unterschiedlichen Ausführungsgeschwindigkeiten von Subgraphen
- Asynchronitäten durch besonders aktive Eingabegeräte / Netreceiver (..) werden durch ein neues Verständnis von "Events" sauber verarbeitet
- Neues "Frame"-Verständnis
Umsetzung:
1. Es existiert ein globaler FrameCounter (GFrame : LongWord).
Weiterhin soll es möglich sein eine Menge von Knoten in einem bestimmten Frame gleichzeitig zu berechnen und Mehrfachberechnungen durch Caches zu verhindern.
Dies wird zum einen dadurch ermöglicht, dass bereits berechnete Datenpakete mit dem Frame gestempelt werden. Alle Caches, deren Frame < GFrame sind veraltet und führen zu Neuberechnungen.
Jedem Frame / jeder Frame-nummer ist eine bestimmte Zeit zugeordnet. Da es immer nur einen aktuell zu berechnenden Frame gibt, existiert auch nur eine aktuelle diesem Frame zugeordnete Zeit (GFrameTime).
Jedoch ist es nicht einer Mainloop vorbehalten diese Zeit hochzuzählen. Vielmehr arbeitet die Mainloop / Scheduler nur noch mit der aktuellen Systemzeit, die sich von Abfrage zu Abfrage naturgemäss ändert. Die Mainloop kennt kein Caching/Quantisierung der Zeit und keine Frames. Sie wird ersetzt durch einen Scheduler bei dem sich verschiedene Knoten registrieren.
Ein Renderer wird sich z.B. 60 mal pro Sekunde aufrufen lassen. (Zur vollen Sekunde und 59 mal dazwischen um möglichst viele Frames mit anderen Renderern zu teilen die möglicherweise die gleiche Taktung haben) Dieser Knoten wird überprüfen ob die dem aktuellen Frame zugeordnete Zeit derjenigen entspricht für die er den Graphen evaluieren möchte. (natürlich gibt es dafür eine möglicherweise Thread-sichere globale Funktion die für eine bestimmte Zeit einen neuen Global Unique Frame ausspuckt)
Mit diesem (neuen?) GFrame wird der Knoten seine Inputs validieren.
Alle Knoten die im Zuge dessen neu evaluiert werden müssen berechnen sich für dieses GFrame und diese GFrameTime.
Ein anderer Knoten der beispielsweise 300 mal pro Sekunde aufgerufen wird (einer davon zur vollen Sekunde) wird jeden 5. Frame bemerken dass möglicherweise nichts zu berechnen ist, da der Renderer für diese Zeit schon ein neues Frame erstellt hat und genau diesen Subgraphen schon evaluiert hat. Der Knoten wird von der globalen Funktion keine neue Framenummer zugeteilt bekommen und möglicherweise nur noch kleine andere Subgraphen zur Berechnung anstossen, andere sind schon gecachet.
Knoten werden immer für die, für sie selbst interessante Zeit, ein Frame berechnen (so wie im Scheduler eingetragen) und nicht etwa für eine beliebige momentane oder von der Mainloop vorgegebene Zeit.
Die meisten Knoten werden nach wie vor über EvaluateCBs von anderen Knoten aufgerufen und geben der Taktung nach wie sie von unten angefordert wird.
Und dann gibt es noch Knoten, die sich immer mitberechnen müssen, damit ihnen nichts wichtiges entgeht. Zustandsbehaftete Knoten, wie Counter, Toggle, LFO, bei denen die Outputs nicht nur von den Inputs abhängig sind, sondern auch davon, was früher mal an den Inputs anlag bzw. in welchem Zustand sie sich aus bestimmten Gründen befinden.
Wenn diese Knopten nur berechnet werden würden, wenn ihre Outputs abgefragt werden, würden sie sich bei Nicht-beobachtung anders verhalten als wenn man hinschaut. Auch das ist natürlich mittlerweile ein 100 Jahre alter Hut, aber zumindest diskutierbar.
Nehmen wir an es gebe Schrödingers Katze nicht, und nennen diese Knoten, die sich berechnen müssen um möglichst unauffällig zu bleiben: Runner
zustandsbehaftete Knoten und präzise Ausgabegeräte: Toggle, Netsend, LFO..
Diese Knoten werden nach einem Scheduling, also nach jedem erzwungenem neuen Frame, aufgefordert sich für dieses global aktuelle Frame zu berechnen. Andernfalls könnten ihnen wichtige Ereignisse verloren gehen.
(Eine andere Methode wäre alle für dieses Frame scheinbar nicht benötigten Zustandsknoten lediglich aufzufordern alle neuen Datenpakete (wenn vorhanden) in ihren Inputs zwischenzuspeichern. Jedoch ist fraglich ob das die maschiene runder macht, da bei erneuter aktivierung alle zwischengespeicherten frames abgearbeitet werden müssten. es handelt sich eigentlich nur um eine Vertagung. Einzig interssant dass es bei den meisten Zeit-basierten Knoten möglich wäre all das nachzuholen. LFOs und Filter sind Funktionen der Zeit. Wenn man Ihnen nachträglich alle vergangenen Frames mit ihren vergangenen Zeiten vorgaukelt werden sie all das verpasste präzise nachholen können.)
Renderer
Der Scheduler könnte typischerweise diese PrepareGraphCBs vor der Zeit aufrufen um dann Renderern die Möglichkeit zu geben im richtigen Moment das Ergebnis präsentieren zu können.
CurrentTime + Preroll >= ScheduleItem.Time -> Call PrepareGraph.
Der Preroll sollte mindestens BackbufferCount / FPS betragen. Da alle interaktiven Einagaben naturgemäss nicht vorrausberechnet werden können kann man auf Preroll möglicherweise auch verzichten.
Generell sollte aber immer zu sehr präzisen Momenten präsentiert werden und zu ungenaueren, etwas vorgezogenen Zeiten neu berechnet werden um auf das present warten zu können.
Sauber wäre eine Implementierung bei der klar ist welcher (für eine bestimmte Zeit gerenderte) Backbuffer bei einem present-Aufruf dargestellt wird. In einem speziellen Debugmode würde angezeigt werden ob veraltete Bilder präsentiert werden. Bei nur einem Backbuffer könnte auf zu späten Aufruf des PresentCBs auch mit Verweigerung des Presents reagiert werden. Beim nächsten Rendern wird dann der Backbuffer einfach überschrieben.
Inputdevices
Inputdevices oder auch der DelayKnoten haben u.U. eine ganze Sammlung von Datenpaketen mit Timestamps, die auf die Auslieferung warten. (Im Falle von Neterceivern kann auch die empfangene Botschaft einen TimeStamp in der Zukunft beinhalten) Diese Knoten könnten in der einfachsten Variante auf Anfrage das älteste Datenpaket mit dem aktuellen Frame stempeln, somit für diesen Frame validieren und für den Graphen bereitstellen. Beim nächsten Frame wird das jetzt ungültige Paket gelöscht.
Diese Methode führt bei sehr aktiven Eingabegeräten zu Überläufen; ausserdem werden die Datenpakete nicht in der Dynamik ausgeführt wie sie eintreffen, sondern auf auf Frames gequantelt, die ein anderer Knoten sich ausgedacht hat.
Eine andere Methode wäre den Eingabegeräten zuzugestehen Global Unique Frames für diese Timestamps zu erstellen. Das funktioniert freilich nur, wenn diese Timestamps noch in der Zukunft liegen, genauer: wenn nicht schon ein GUF für eine spätere Zeit erstellt worden ist. (was gegen preroll sprechen würde)
Noch genauer: Die Eingabegeräte, die möglicherweise in anderen threads ablaufen reagieren bei ankommenden Events mit einem threadsicheren Eintrag des timestamps im scheduler, ohne ein GUF zu generieren. Es handelt sich lediglich um eine Registrierung eines zu berechnenden frames in der Zukunft. (dadurch können sich diese Ereignisse noch etwas sortieren) Es wird auch kein explizit zu berechnender Knoten für dieses frame angeführt. (wie beim renderer, der stur seine Taktung beibehalten möchte) Stattdessen werden bei Berechnung dieses Frames nur die Runner aufgefordert sich neu zu berechnen.
Runner
Ein Nachteil dieser unregelmässigen Frames ist sicher, dass Frame-basierte Knoten wie Toggle (immer auf 1) andere Ergebnisse liefern wenn sie häufiger oder weniger häufig aufgerufen werden. Auch Frmae-basierte Filter (also gepatcht, da alle eingebauten Filter Zeitbasiert sind) reagieren dann etwas holprig. Jedoch ist das by design auch gewollt. Man möchte ja auch subgraphen eine schnellere Evaluierung ermöglichen, als das ein Renderer anzeigen kann, und genau da muss es diese Art von "Zwischenframes" geben. Ein Kompromiss wäre ein Modus der Eingabegeräte, der bei Eintreffen eines Events erstmal kein Zwischenframe erzeugt, sondern erst bei Überläufen mit derartigen Methoden reagiert.
Runner zeichnen sich dadurch aus, dass bei gleichen/konstanten Inputs die Outputs sich ändern können. Der Output unterscheidet sich je nach Zustand. Man kann noch enger unterscheiden zwischen Frame-basierten, Eingabe-basierten und Zeit-basierten Zustandsknoten.
Bei KONSTANTEN Inputs:
Frame-basierte Runner können sich selbst bei konstanter Zeit ändern. (Toggle, Counter, ..)
Zeit-basierte Runner können sich nur bei fortlaufender Zeit ändern. (Filter, LFO, ..)
Eingabe-basierte Runner können sich selbst bei konstanter Zeit ändern. Sie geben ihre Events nur einmal (in einem Frame) ab.
Ein Graph überhalb eines Inputpins kann also entweder konstant sein, sich bei fortlaufender Zeit ändern, oder aber sich auch potentiell immer ändern. Darüber hinaus kann eine Eingabe per Inspektor zur kurzzeitigen Änderung eines normalerweise konstnaten Graphen führen. Ein weiteres Flag (manuallychanged) hierfür kennzeichnet alle Knoten/Pins unterhalb der Eingabe.
Beim Einfügen eines framebased Runners wird der komplette Graph unterhalb dieses Knotens auf framebased gestellt. Beim Einfügen eines timebased Runners wird der komplette Graph unterhalb dieses Knotens auf timebased gestellt (wenn nicht schon auf framebased).
Mit dieser Optimierung können bei Evaluierung konstante Graphen (nicht manuallychanged) getrost übergangen werden.
Bei Eingabe-basierten Runnern ist eine weitere Optimierung denkbar. Sie könnten als konstante Knoten auftreten und nur bei eingehenden Events manuallychanged Flags verteilen. Dies dürfte aber nicht aus dem Thread heraus geschehen, sondern müsste zeitversetzt vor dem nächsten Frame gemacht werden.
Auch Frame- und Zeit-basierte Runner könnten (solange ihre Inputs wiederum konstant sind) in Spezialfällen als konstant auftreten. Ein Toggle dessen Input konstant auf 0 steht muss nicht berechnet werden...
Loops
Ein weiterer Coop wäre die Implementierung von Loops.
Ein Loop-Knoten könnte beispielsweise auf das Eintreten einer Bedingung warten. (falls diese nie eintritt sollte auf jeden Fall eine maximale Anzahl an Durchläufen einstellbar sein)
Der Knoten würde sich vom Scheduler aufrufen lassen, ein GUF erstellen und seine Inputs validieren.
Falls die Bedingung nicht eintritt (der entsprechende Pin gibt 0 zurück), würde er ein neues Frame erstellen und für dieses neue GFrame den Graphen erneut validieren. Bonus: keine neue Zeit, d.h. Graphen mit timebased Flag müssen nicht neu berechnet werden.
(Es ist sogar eine Variante denkbar, bei der sich der Loop-Knoten nicht selbst im scheduler einträgt, sondern nur auf ein EvaluateCB reagiert. Wenn er für eine bestimmte Zeit und ein bestimmtes Frame evaluiert werden soll, kann er darauf mit Berechnung von vielen Frames zu genau dieser Zeit reagieren. Alle für das urpsrüngliche Frame schon validierten Knoten (vor dem Aufruf von Loop.EvaluateCB) müssten bei Abschluss von Loop.EvaluateCB auf noch unklare Weise auch für das nun aktuelle Frame als gültig markiert werden.)
Eine andere Variante wäre ein Loop-Knoten der sich der Zeit, die er verbraucht bewusst ist und sich einfach immer wieder im Scheduler einträgt. Falls die Bedingung false zurückgibt, würde dieser sich zeitnah zur aktuellen Systemzeit wieder im Scheduler eintragen (oder entsprechend eines FPS InputPins). Durch die Rückgabe an den Scheduler ist aber eine Zusammenarbeit mit Input-devices und Renderern möglich. Falls man sicherstellen möchte, dass trotzdem nur tatsächliche Ergebnisse des Loops an den umliegenden Graphen weitergeleitet werden, muss man einfach vom S+H Knoten Gebrauch machen und Ergebnisse erst bei erfolgreicher Bedingung sampeln.
Events
Die grosse Frage bleibt: Müssen wirklich alle Runner ständig evaluiert werden, weil sich potentiell in diesem Frame etwas geändert hat?
Kann man nicht auch die Framerate für diese Knoten besser einstellen ohne dass ihnen Events (bspw. von Eingabegeräten) verloren gehen?
Eigentlich ist es doch so:
Man möchte, dass auf Eingaben zeitnah reagiert wird. (im Inputdevice einstellbar: eigene Frames erzeugen oder versuchen mit der unten anliegenden Framequantelung zurecht zu kommen)
Jedenfalls sind das echte Events, auf die reagiert werden soll. (freilich nur von Knoten, die tatsächlich davon abhängen) Und auf Eingaben über den Inspektor soll auch möglichst prompt reagiert werden. Auch hier kann notfalls ein Frame eingefügt werden. (Es könnte sein, dass der bearbeitete Knoten sehr selten überprüft wird.)
Was gibt es sonst noch für Events? Klar kann man sich vorstellen, dass Zeit-basierte Knoten auch Frames einfügen. (LFO, einstellbar: Jede x*Periode mal ein Event generieren. Auch Filter könnten bei Beendigung der Animation ein Event abschicken.) Jedoch: Zeit-basierte Knoten ändern sich (wenn sie tatsächlich laufen) ununterbrochen. Sie müssten unendlich viele Events abgeben, da sie bei jedem noch so kleinen Zeitunterschied ein anderes Ergebnis abgeben würden. Ein Change Knoten würde ständig 1 ausgeben und der unten angeschlossene Toggle würde ständig schalten. Je häufiger hier abgefragt wird, umso häufiger ändern unten angeschlossene Frame-basierte Zustandsknoten ihren Zustand (Toggle).
Aus diesem Dilemma kann man sich nicht befreien. Es ist einfach so: Je öfter evaluaiert wird umso unterschiedlicher das Ergebnis von Frame-basierten Algorithmen.
Deshalb ist es so wichtig für jeden Teil im Patch die Kontrolle zu behalten wie oft und unter welchen Umständen der jeweilige Subgraph evaluiert wird.
Was gibt es sonst noch für Events? Ein LFO oder ein ständig aktiver Toggle (1) wird mir immer ein Event liefern wenn ich ihn frage. Das sind also keine echten Events.
Unter welchen Umständen möchte man, dass LFOs in nicht aktiven Subgraphen trotzdem aktiv sind, obwohl für keinen Renderer interssant?
Muss man nicht zwischen globalen und lokalen Frames unterscheiden? Globale Frames zwingen jeden Runner sich abzudaten, lokale interessieren sich nur für ihren Subgraphen? Eingabegeräte, die auf Abholung der Daten einfach warten reagien nur auf globale Frames um sicher zu stellen, dass alle von der Eingabe erfahren?
Echte Events werden tatsächlich von oben nach unten durch den Graph geschickt. Unechte warten in einer Queue des Inputdevices auf Abfrage.
Auch die Eingabe per Inspektor kann u.U. auf die nächste Evaluation warten. (Der per GUI gestartete LFO würde erst starten, wenn der Subgraph wieder im Einsatz ist.)
Nehmen wir ersteinmal an, dass bei Events durch Eingabegeräte oder GUI tatsächlich ein Frame eingefügt wird. Der entsprechende Knoten würde sich sobald als möglich zurückrufen lassen und die Datenpakete durch den Graph pushen. Dann wäre plötzlich interessant was unten dranhängt. Wenn unten frame- oder zeit-basierte Knoten hängen, sollten diese vom Event benachrichtigt werden. Pushe so lange durch den Graphen, bis unten kein frame- oder zeitbasierter Knoten mehr dranhängt. (Netsender sind auch framebasiert) Hängt unten nur noch ein Vertexbuffer Join und Quads und Renderer dran, dann kann das warten.
Hätten wir dann nicht so etwas ähnliches, wie unseren jetzigen Graphen? Alle Zustandsknoten würden von tatsächlichen Änderungen etwas mitbekommen. Nur Teile vom Graphen, die tatsächlich nichts zur Ausgabe auf einem Renderer beitragen, würden nicht im Hintergrund vor sich hin laufen. Alle Abläufe im Hintergrund, die sich alleinig auf autonome Algorithmen (nicht von Eingaben / echten Events abhängig)stützen würden nicht mehr evaluiert werden. (LFO schaltet nun keine verborgene Slideshow durch...)
tja.
implementierbar ist alles:
- Patches, die auf HOT gestellt werden können (alle enthaltenen Runner reagieren auf jedes Frame)
- Inputdevices, die nur auf Anfrage Datenpakete rausrücken, dann aber allen abhängigen Knoten die Daten zupushen.
- Loop Knoten, die pushen können
- Delay-Knoten die mehrere Frames parat haben
- noch nicht erörterte Threads einbauen
- etc.
TODO:
Anwendungsfälle konstruieren. Alle erdenklichen Patches auf diese Fragen hin untersuchen.
diskutieren
sbns comments
also: Exzellenter startpunkt für eine diskussion:
Szenariovorschläge:
- Ein subgraph rendert video mit 30fps
- Ein anderer renderdert eine bildschirmuhr mit 1fps, die als textur oben verwendet wird
- Ein subgraph rendert soundsamples mit 44100/vectorsize fps
- Ein subgraph rendert ausgangswerte eines drumcomputers für den audiograph mit 120*16bpm
- Ein subgraph filtert eingehende datenwerte eines sensors sobald sie ankommen.
- Ein subgraph generiert webseiten, sobald sie angefragt werden.
Vorab:
das jetzige system (alles passiert absolut zeitgleich) hat sich als unschätzbar praktisch und übersichtlich (im vergleich zum eventbasierten maxmsp) erwiesen. Das sollten wir beibehalten. Ich finde es immer atemberaubend, wie gut das in vvvv funktioniert, das alles im selben frame berechnet wird, und wie gut man um alle synchronizitätsprobleme herumkommt.
Will man verschiedene uhren gleichzeitig ablaufen lassen, muss es eine graphische metapher dafür geben. Die können Exposable Subgraphs sein oder das schlichte "ein fenster=eine mainloop" (letzteres wäre mein vorschlag)
das verbinden von subgraphen mit verschiedenen frameraten ist immer ein mathematischer kompromiss; je nach anwendungsfall gibt es bestimmte filterverfahren, die sinnvolle übersetzungen vornehmen, ähnlich den resample-modes. Denkbar etwa auch prädiktive filter (z.b kalman filter) Welchen filter man zum übersetzen nimmt, muss explizit einstellbar sein. Die filter sind z.t. nicht trivial. Letztlich also gute kandidaten für knoten, ähnlich damper etc.
loops:
Loops über mehrfachevaluation durchzuführen, kommt mir mehr wie ein hack vor.
Klar geht das, aber ich denke, es müsste einen abstrakteren weg geben, das zu tun. Wie verbindet man unterschiedlich loopende subgraphen, in welchen subframes kann man sie wie verbinden? Wie macht man while schleifen, die von zwischenergebnissen abhängen?
Wenn man das will, dann nur über prozedurvariablen. Wie auch immer das geht.
Aber an welchen stellen werden loops wirklich gebraucht? Ist es nicht einer der grossartigkeiten von vvvv, dass man schleifen nicht braucht? Gibt es nicht immer eine lösung mit knoten und pins, die letztlich einfacher zu benutzen ist? So etwas wie spectral-knoten, cross, resample, sift, binsizes etc.
Oder eine kleine textuelle sprache im pythonpascalperlassembler-knoten?
Wo brauchen wir schleifen?
- sanchs Lindenmayer-systeme mit variabler auflösung?
- performance-optimierung, wenn man nicht immer mit der kompletten potenzmenge arbeiten will, und nur teile davon berechnen mus
gregsns comments
gute Szenarien! mit sowas konkretem tu ich mich manchmal schwer.
und noch vorab: mit dem zeitgleich bin ich absolut deiner meinung.
Die Frage nach den Filtern ist berechtigt. Bin in dem Text immer davon augegangen, dass Graphen auch in mehreren Taktungen laufen. (immer wenn von unten angefragt wird, wird auf jeden Fall neu berechnet) Damit bräuchte man keine Filter. Aber man hätte auch herzlich wenig Kontrolle über die tatsächliche Aufrufhäufigkeit. Ich denke man braucht so etwas wie einen poll Knoten. (im Renderer/NetSender möglicherweise schon integriert) Jedenfalls gibts den auch einzeln. Mit diesem Knoten pollt man den Graphen in einer bestimmten Frequenz (kann man an jeden outputpin anschliessen).
Diesen Knoten könnte man auch sync nennen, denn wenn man unten an ihn was anschliesst wird das oben anliegende gefiltert nach unten gegeben. Jedoch: wenn unten mal ein EvaluateCB anschwirrt, dann werden nicht die inputs evaluiert, sondern die gefilterte, gecachete variante vom letzten poll zurückgegeben.
Möglicherweise kann man auch mehrere Werte durch diesen Knoten synchronisieren. (Kann man schön am Ausgang eines Subpatches plazieren.) Ob der dann noch im gleichen Thread pollt ist dann auch schon fast egal(?)
funktioniert für Szenario:
- Ein subgraph rendert video mit 30fps
- Ein anderer renderdert eine bildschirmuhr mit 1fps, die als textur oben verwendet wird
ich mach mich ja gern frei von allen (bisherigen) Konventionen:
das mit dem pushen gibt's also. Eingabegeräte pushen und können Graphen aufwecken. Dafür braucht man nur noch den Knoten OnPush. Dieser reagiert auf ein push einfach mit einem Bang. Er könnte einen Monoflop triggern, der für eine gewisse Zeit (=Filtertime) einen pull Knoten aktiviert.
praktisch für:
- Ein subgraph filtert eingehende datenwerte eines sensors sobald sie ankommen.
Push ist keine Zauberei: Der Graph bietet eine Funktion, die einfach alle EvaluateCBs von oben nach unten aufruft. (Nur ein Knoten kann das aufhalten: sync/poll.) Jedenfalls ruft ein Eingabegerät diese Funktion auf um all seine Daten unters Volk zu mischen. Wird mit vielen Threads gearbeitet, muss man das Eintreffen von Daten aber als eine Art Interrupt betrachten. Der Knoten betritt eine critical section, die erst betreten werden kann wenn alle anderen Threads ihr Frame beendet haben~. hm. ~ Die Push-Funktion wird aufgerufen und die critical section verlassen. ~
genial: es gibt natürlich nicht nur den "OnPush"-Knoten, sondern auch den push-Knoten (möglicherweise in den Eingabegeräten schon integriert) und: möglicherweise auch in einem Filestream-Node integriert. Unten am Renderer stellt man 0 fps ein (falls poll im Renderer integriert) oder man hängt einfach keinen poll-Knoten an. Dann wird dieser Graph nur gepusht. Wenn ein Frame vom DirectShow-Graphen kommt wird gerendert. ganz einfach.
loops
ja, naja. es wäre natürlich cool möglichst viel was man als built-in knoten hat auch patchen zu können.
Beispiel: lineaspread ist patchbar mit i knoten und maprange. (gut, den enum müsste man sich noch bauen dürfen)
so sollte das auch mit spectral knoten sein. oder zumindest wäre es ziemlich cool.
so baut man sich einen add spectral knoten:

old sketch:
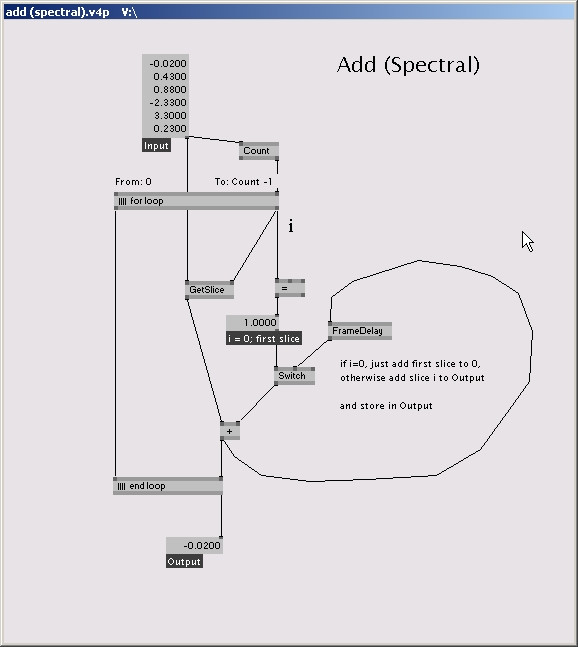
in meinen augen kein hack mit der mehrfachevaluation.
eine texturelle sprache kommt mir dagegen eher vor wie eine kapitulation. am liebsten würde ich die effekte auch raushauen (nur weil textuell)..
naja passiert automatisch wenn man mal das alles neu implementiert :) :| :(
also ganz ehrlich: mit binsizes kann man mich jagen. mit resample sowieso. da werden irgendwelche daten aufgeblasen, die nur einmal vorhanden sein müssen. man braucht nur eine strukturierte Form des Zugriffs (nächstes Kapitel)
tebjans comments
zur mainloop geschichte:
ich bin sehr stark dafür, dass jeder patch seine mainloop hat. patches und subpatches sind (auch) dazu da, um teil-probleme zu lösen, und das passt ganz gut zusammen finde ich. dann ist also ein patch ein subgraph, damit hätte man auch diese frage schonmal gelöst und es ist für den user wieder übersichtlicher weil es einfach zu erklären ist. wobei man einem patch natürlich auch sagen können muss, ob es sich einfach ans mainloop vom parent patch hängt, weil es nur zur übersichtlichkeit gemacht wurde, und nicht um ein anders problem zu lösen.
die letztlich komliziertere frage dabei bleibt natürlich, wie wird mit patches kummuniziert, die schneller oder langsamer laufen.
sbns comments
@add spectral: ok. scheint also denkbar zu sein. aber was passiert in den ersten diagramm, wenn ich den ausgang von dem + mit einem transform/quad/renderer verbinde genau? wird das dann mehrfach gezeichnet?
nein. der renderer wird ja nicht vom "for end" aufgefordert sich zu evaluieren. und dann gilt weiterhin: das, was sich nicht berechnen muss berechnet sich nicht. (poll-graph) wenn dann der renderer mal auf die idee kommt seinen graphen zu evaluieren, dann bekommt er nur noch das letzte finale ergebnis vom + zurück, denn der "for begin" arbeitet nur, wenn er vom "for end" aufgefordert wurde.
und ist das wirklich irgendwie coolertoller als ein for-konstrukt in einer textuellen sprache? oder letztlich genauso umständlich?
ein for-konstrukt ist ja nicht wirklich umständlich. das ist eigentlich eine sehr einfache sache. jeder, der mit vvvv bisher über die ersten zwei kleinen patches hinausgekommen ist, ist von der kategorie, dass er for schleifen verstehen kann. jedoch klar von textueller programmierung geklaut. stimmt schon.
und wie mache ich eine while schleife: etwa apfelmännchen:
iteriere
begin repeat x:=f(x); i:=i+1 until (x<1) and (i<100) end;
genau so. mit repeat und until. bei until kannst du ausser nur i und x zu übergeben auch noch bangen wenns genug ist und until die sache abbrechen soll. Pin: "Until" oder "Stop"
und wie kann ich im tooltip/inspektor verstehen, was abgeht? das war ja auch ein klassischer pluspunkt von vvvv?
wie oft updateview aufgerufen? hm. ich kann dir noch nicht genau sagen von wo der aufgerufen wird.
jedenfalls: debuggen von for ist noch viel schöner als überall sonst in vvvv. sonst muss man ja immer ein mainloop anlegen, damit man mit den daten was anfangen kann. den graph ganz anzuhalten ist momentan schon mal gar nicht möglich. dann kann man nichts mehr machen. (da macht debuggen in delphi mehr spasss) beim loop knoten muss man nur den To-Pin entsprechend einstellen und man sieht genau den schritt den man sehen möchte.
@onpush und pull: hmm.
wie wäre es einer nodeverbindung am MainLoop knoten, die man mit einem UDP/RS232/Tokenizer verbinden kann?, also allen knoten, die eine evaluation anstossen müssen.
also eine logische verknüpfung? hm. habe das gefühl, dass man da nur einige spezialfälle abdecken kann, aber nicht so weit kommt tatsächlich verschiedene graphen und deren ausführungsgeschwindigkeit wirklich managen zu können.
szenario: empfange daten von der seriellen schnittstelle, evaluiere in dem moment wo ein carriagereturn über die leitung kommt.
szenariovetiefung: die daten sind inkrementelle wertänderungen eines drehgebers. d.h man will mitzählen wieviele davon ankommen, und damit mit 30fps ein grapisches objekt rendern. wichtig ist also, keine zu verlieren. und wie kann man sie ideal filtern?
rs232 pusht in Integral-Knoten, S+H wird nur ausgeführt, wenn RegExpr CR entdeckt. dann gleich sync knoten, der die pushes entgegen nimmt und in eine queue setzt. der renderer unten pollt mit 30 fps und holt sich die werte vom sync knoten, bei dem man auch einen filter mode einstellen kann.
@binsizes, resample, jagen:
ich rede nicht von der implementation, sondern davon, das man mit den genannten knoten um schleifen komplett herumkommt. das finde ich konzeptionell spannend.
ok war scharf ausgedrückt. hm. jedoch braucht man mindestens eine ausgefuchste implemntierung von multidimensionalen spreads um cross und resample aus performance-sicht schön zu gestalten.
ABER: damit kann man noch nicht alles machen. in vvvv wird mittlerweile gott sei dank jeder knoten komplett durchgerechnet bevor der nächste drankommt. das schränkt einen aber so weit ein, dass man ohne loop knoten keine sachen patchen kann, wo ein slice in einem spread vom vorherigen slice abhängt. ohne loop sind spectral-mässige knoten nicht zu patchen.
- sanchs Lindenmayer-systeme mit variabler auflösung?
ist nicht patchbar solange es keinen spezialknoten gibt, der für einen matrizen nun innerhalb eines spreads aufmultipliziert und alle zwischenergebinsse auswirft. denkbarer knoten, aber schade, dass nicht patchbar zumal alle operationen ja eigentlich vorhanden.
hier noch ein anderer visueller vorschlag.
hat noch ein paar wahnsinnigkeiten:
- jeder subpatch hat seine eigene mainloop. über einen noch nicht völlig durchdachte raffinierte logik kann jeder subpatch seine mainloop selbst aktivieren und deaktivieren.
- gleich benannte ein- und ausgänge bilden ein verstecktes framedelay.
- so also das beispiel, dass auch gleich die ganze for-schleife selbst implementiert:

- also endlich auch ein grund den tollen boxmodus zum laufen zu bekommen
Datenstrukturierung
Ziele:
- Elegantes Ersetzen von Binsizes; Effizienteres Umsetzen von Resample, Cross
- Bessere Modularisierung
- Mächtiger Entwurf der alle Cachingfragen klärt
Erste Worte
Der erstaunlich komplex und erdrückend wirkende Begriff "multidimensionale Spreads"
soll hier entsprechend "komplex" erklärt werden. Dieser wie auch obiger Text sind keine
Einführungen in ein Thema aus usersicht, sondern sollen meine Gedanken ordnen, die von einem
unklaren Konzept mit unklaren Zielen fortwährend zu immer klareren Formulierungen, Axiomen,
Gedanken führen könnten. Ausserdem sind hier auch z.T. Fragen der Implementierung
ein Thema, da all diese Ausführungen
- ein theoretisch fundamentiertes Modell entwickeln sollen
- dieses dann aber auch in effizienten Algorithmen münden soll.
Einführung
Der Schritt von eindimensionalen Spreads wie sie jetzt existieren zu multidimensionalen ist
ähnlich dem von einem einzigen Wert zu dem jetzigen Spread. Man muss erstmal dieses neue Prinzip
verstehen
(
- wie übertragen sich Spreads von Knoten zu Knoten?
- wie interagieren verschieden lange Spreads an den Inputpins miteinander?
- wie ergibt sich die Spreadlänge am Ausgangspin eines Knotens?
)
oder manchmal auch eine schlecht durchdachte Version implementieren um so einen Paradigmenwechsel
selber zu verstehen. (Es gab Zeiten da hatte jeder Knoten einen "Spreadcount" pin...) Natürlich ist
man vor solchen Design"fehlern?" nicht gefeit. Zum Beispiel sind auch in dem bisherigen eindimensionalen
Spreadmodell noch ein paar Themen nicht komplett ausgestanden:
(
- wie geht man mit Fehlern in Knoten um (Ausgang: leerer Spread?)
- oder was passiert wenn der Spread eines Pins leer ist?
- gibt es nur leere Spreads oder auch _leere Slices_?
(um die "Nichtdefiniertheit eines Slices" / "Fehler bei der Berechnung eines Slices" anzuzeigen)
- wie geht ein Knoten mit leeren Slices in den Inputpins um?
)
Jedenfalls denke ich dass der Schritt in die Multidimensionalität noch eine Dimension mehr
Fragen aufwirft und deshalb bedarf es hier eines längeren Textes bzw. der nötigen Geduld und Musse.
Ich werde ersteinmal auf die abstrakte, gedachte Struktur zu sprechen kommen.
Wir werden die neuen Datenstrukturen, die nun über Links übertragen werden können auch an ein paar Knoten
überprüfen. Wir werden versuchen nur kleine Szenarien entwickeln, die ein jeder user meistern sollte.
Die Diskussion ob es sich hier noch vvvv handelt oder um ein unverständliches Expertensystem, das
für einen ganz bestimmten Schlag von Experten nur interessant ist sollte dann mündlich irgendwo unter
vier Augen besprochen werden ;|
Im weiteren Verlauf des Textes werden dann Implementierungen mehr und mehr angedacht, bei der
Performanceüberlegungen und Komfort für den Knotenschreiber die wichtigsten Korrektive darstellen.
Vereinbarungen
- Knoten können über Pins Daten austauschen.
- Es ist von Vorteil wenn möglichst viele Knoten kompatibel zu einander sind
- Daher braucht man klare Schnittstellen
- Schnittstellen können dem Benutzer verborgen bleiben
(abstrakte Verbindungen, die Texturen, Matrizzen (..) übertragen oder nur Zuordungen darstellen)
- Durch solche Verknüpfungen können bilateral Informationen ausgetauscht werden, Magie erzeigt werden
- Die Didaktik und Lesbarkeit (durch den User) kann bei solchen Verbindungen zu kurz kommen
- Schnittstellen, die Daten nur in eine Richtung übertragen können und dies immer auf die
gleiche Art und Weise tun sind zu bevorzugen.
- Skalierbarkeit der Datenmenge ist ein mächtiges Konzept
- weitere Strukturierung der Daten führt im besten Fall zu:
- user: weiterer Modularisierung (auf Datenebene, nicht auf Subpatchebene)
- user: Erleichterung bei der Handhabe von "eigentlich" multidimensionalen Spreads (Cross 2d, Queue mit Spreads per Frame, keine Binsizes...)
- user: Erleichterung der Skalierbarkeit von schon bestehenden Patches
- user: klarere Darstellung im GUI
- dev: Vereinfachung / Standardisierung der Knotenimplementation von Knoten, die mit "Teilen eines Spreads" hantieren
Basics
Ziele:
- Die Datenstrukturierung sollte anhand anderer verfügbarer Modelle leicht erklärt werden können.
- Sie muss also einfach sein um userseitig handhabbar und app.seitig effizient zu sein
- Sie sollte komplex genug sein, um erstaunlich viele Anwendungsfälle abzudecken und genügend gängige Spezialfälle enthalten (optimierbar, bessere GUI für diese Standardgraphen)
Die zu übertragende Struktur sollte anhand eines einfachen Graphen aufzuzeichnen sein.
Bäume
Eine gängige hierarchische Ordnung von Daten ist mit Hilfe von Foldern zu erreichen.
Man kann auch von Gruppen oder Listen sprechen. Listen könne wieder Listen enthalten.
Mit diesem Prinzip kann man hierarchische Baumgraphen erstellen die eine Wurzel haben.
Beispiele:
_leer_
()
-
_Liste_
(4, 8, 3)
4 8 3
4
8
3
_Baum_
(4, (7, 1), 3)
4
7 1
3
- Liste
-4
- Liste
-7
-1
-3
_leer_
()?
-
_Baum mit enthaltenen leeren Listen_
(4, (7, 1, ()), (), 3)
4
7 1 -
-
3
- Liste
-4
- Liste
-7
-1
- leere Liste
- leere Liste
-3
_Baum mit mehreren Ebenen_
(1, (2, (3, (4, (5, 6)))))
durch 2d-matrixdarstellung nicht darstellbar
- Liste
-1
- Liste
-2
- Liste
-3
- Liste
-4
- Liste
-5
-6
Spezialfälle
- Spezialfälle sind 1d-Listen, Grids, Quader, mehrdimensionale Räume
warum? man kann doch ein Grid durch eine Menge von Listen nachbilden:
1 2
3 4
jedoch ist ein "abgeschlossener" Raum wesentlich klarer zu beschreiben.
(und dadurch sehr wahrscheinlich auch effizienter zu implementieren)
um ein s/w-bild mit 1024*768 punkten zu beschreiben bräuchte man z.B. 768 Listen, die je 1024 Farben verwalten.
anstatt der 768 Listen würde man diese Struktur doch lieber als ein Raster aus 1024*768 Farben beschreiben.
- weitere Spezialfälle von 1d-Listen sind n-Tupel / Vektoren
2d:x: 0, y: 0
3d:x: 0, y: 0, z: 0
4d:x: 0, y: 0, z: 0, w: 1
warum? das sind doch nur 1d Listen.
ja, aber sehr gängige und oft benutzte!
Die Einführung der Tupels erleichtert auch das Verständnis der Mehrdimensionalität.
Es besteht nämlich ein krasser Unterschied zwischen einer Struktur mit 3 Ebenen / Dimensionen und einer Struktur die
3-d Vektoren / Tupel enthält:
die ecken eines _3d_ würfels:
(1, 2), (3, 4?, 5, 6), (7, 8)?
eine Liste mit einigen _3d_ Vektoren:
0, 3, 7,2, 2, 2,4, 1, 6,0, 0, -1)
die Kombination von beidem wäre die Punktwolke mit allen 8 Ecken eines Würfels:
0, 0, 0,1, 0, 0), 0, 1, 0,1, 1, 0?, 0, 0, 1,1, 0, 1), 0, 1, 1,1, 1, 1)?
es ist wichtig den Unterschied zu verstehen. man wird weiterhin oft mit Vektoren arbeiten, da man es
in 2d und 3d Computergraphik häufig mit 2d-4d Vektoren zu tun bekommt. Also ist es nur schlüssig genau
diese "Spezialfälle" zu unterstützen und dem User als Vektor darzustellen. Das erhöht die Lesbarkeit des GUIs.
Vektoren sind aber kein integraler Bestandteil um das System aufbauen zu können. Sie sind optional.
Container
Wir haben also Listen und Räume.
Diese Strukturen enthalten Atome, mit denen Knoten als Einheit umgehen können:
ein Atom kann sein:
- Zahl
- Farbe
- Enumeration
- Text
- Textur
- Vertex
(-Vektor, Matrix)
(-Triangle (nur die 3 Indices, also ein Integer-Vektor))
(...)?
man kann sich sicher noch weitere Atome denken.
Es soll hier aber mehr darum gehen, dass all diese Atome in Listen und Räumen strukturiert werden können.
Um aber Zuweisungskompatibilät schon beim Verbinden von Pins überprüfen zu können, dürfen Strukturen
niemals Gemische aus verschieden Atomtypen enthalten.
Es wäre zwar denkbar Gemische zuzulassen, wenn ein Pin angibt, dass er mit Vektoren und Farben umgehen kann,
jedoch sollte an diesem Punkt keine unnötige Komplexität eingebaut werden. Ein Konvertierungsknoten, der
möglicherweise nichts macht ist immernoch klarer als jegliche Form von gemischten Strukturen.
Exkurs Vektoren:
Wenn man also nur z.B. als Atomtyp einen 3d-Single-Vektor (nativer directx-vektor) hat, ist ein Wrapper, der
diese Struktur in eine um 1 Dimension grössere Struktur mit Zahlen umwandelt, einfach denkbar. Es ist klar dass dort
nicht einmal ein 3d Vektor steht und dann wieder ein 2d Vektor. Im Falle eines 3d-Double-Vektors und der
Annahme dass Zahlen auch immer Double sind handelt es sich nur um eine Veränderung der Struktur.
Das ganze dient nur um Knoten, die nur mit Zahlen umgehen können diese mit einer entsprechenden Struktur zu versorgen.
OLD:
multi input verwandte themen:
- send receive jumper mechanismus erweitern
- on connect cardinalität der entstehenden verbindungEN checken
- graph bzw. nodepins können mit mehr als einem input umgehen und alle inputs entsprechend validieren.
- wie verhgält sich der slicecount des input pins?
- upstreampin macht nur bei cardinalität 1 sinn
- sollen etwa alle nodepin clients mit mehreren verbindungen umgehen können?
- an welcher stelle setzt ein slice index buffer an? (nur nodepin?)
- an welcher stelle setzt ein pin index buffer an? (nur nodepin?)
- große lösung (abstrakter datenpin) erfordert eine prüfung der delphi strings.
- ist der pointerbuffer ein kompilat aus slice index buffer, pin index buffer, data buffer? wann wird er erstellt oder birgt er einen zu großen overhead und wäre nur in einem compilierten graphen von vorteil?
todo: großen und kleinen ansatz trennen
anonymous user login

Shoutbox
~4d ago
~5d ago
~10d ago
~13d ago
~24d ago
~24d ago
~1mth ago
~1mth ago
~2mth ago
~2mth ago