Dynamic VL Plugin Reference
Cloning a Template
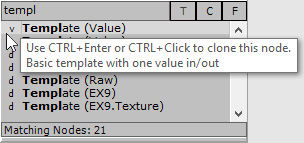  |
In order to create a dynamic VL plugin doubleclick in a patch to open the nodebrowser. Type "Template" to get a list of templates which you can choose to start from. Choose one of the templates prefixed with v and press CTRL+Enter or CTRL+Click on it to clone it. The two options you have is:
Where stateless means that your plugin does not store a state, ie. it is not saving values for re-use in the next frame. This choice is only offered here to save you some clicks later. You can still change your mind at any time in the VL editor. In the "Clone Node" dialog that now shows up choose a unique Name and a Category for your node. Specifying a Version is optional, see NodeAndPinNaming. If the vvvv patch in which you're cloning in is not yet saved you'll also have to specify a path where to clone the VL template to. It is therefore always recommended to save the vvvv patch first because then the clone conveniently goes to a subdirectory "\vl" next to the vvvv patch. Press Clone to see your plugin appear in the patch. Rightclick the node to open the VL editor. |
Defining Pins
 VL editor. Adding a new Input.
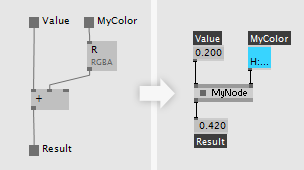 VL editor and the node in vvvv.
|
There are two ways to create input and output pins in VL:
You can always rename a pin by doubleclicking its label. For input pins you can set a default by pressing the middle mousebutton on it or selecting Configure via the rightclick-contextmenu. Initially a pin has no type specified and it will automatically infer its type from the pin it is connected to. This can be convenient but it is also good practice to annotate a pin with a specific type. To do so middleclick a pin to open the TypeBrowser and enter the name of a type. The following is a list of most commonly used types:
For a pin defined like this, VL will always only see a single value, even if a spread is connected in vvvv. See Think slice-wise below. |

Update
|
The Update operation is the heart of your plugin. It is called every frame. Here you do the main calculation of your plugin. If you're looking for a section to initialize some parts of your code (ie. run them only once), see the next section (Create). |

 |
If you annotate the type of an input to be of: Spread<T> then your plugin is operating on bins instead of slices. So in this case with every call of Update VL receives a bin (ie. subset of the incoming spread). Still you don't have to worry about multiple consecutive bins, only think about operating on one bin. The calling of your operation for multiple consecutive bins happens automagically. |
Create: Initializing Stuff
|
You'll use a constructor if you have parts of your code that only need to run once. Note that a constructor is optional and therefore the template doesn't show its usage. |


Dependencies
 Adding a reference to another VL document.
|
By default each VL document depends on the VL.CoreLib.vl package, which gives you access to the VL Core library nodes. You can add dependencies to other packages or VL documents via the document-menu: Dependencies You'll then have access to all nodes that are defined in the referenced package or document. |
Debugging
 Inspecting a value in an IOBox and on a link.
|
In order to inspect the value of a pin simply hover it with the mouse or start a link from it and then middleclick to create an IOBox that will always show you the pins current value. |
Project Structure
 The Document Patch (Alt+P).
|
Typically a simple plugin will consist of a single VL document with multiple patches and references only to the default dependencies (like the VL.CoreLib package). You can get an overview of all elements in your document by viewing the Document Patch which you can always reach via ALT+P. It shows you all Classes, Records, Operations and Utility Patches the document holds. Still from that simple structure you can expose multiple nodes to vvvv. You can have any vl datatype or operation show up as a node in vvvv. |


|
To make sure an operation or datatype is non-generic uncheck its Generic indicator. In case all pins already have a type inferred now all is fine, otherwise certain pins may show an error indicating that they need a type annotation. |
Fine Print
anonymous user login

Shoutbox
~22h ago
~9d ago
~17d ago
~1mth ago
~1mth ago
~1mth ago
~2mth ago
~2mth ago